Lösungsalternative: pdftotext bearbeitet von ursus contionabundo 09.02.2019 09:06 > Sämtliche Versuche, das PDF zu konvertieren, generieren noch viel mehr Datenmüll. Ich sags mal so: Wenn das PDF (z.B. aus LaTeX oder dvi) **generiert** (nicht mit einem Treiber als Grafik pder Postscript/PS gedruckt oder vom Faxserver aus einem Tiff umgewandelt wurde ) wurde, unverschlüsselt ist **und Tabellen enthält**, dann habe ich mit [pdftotex](https://linux.die.net/man/1/pdftotext) gute Erfahrungen gemacht. **1. Versuch** ~~~ pdftotext -nopgbrk -layout datei.pdf datei.layout.txt ~~~ [](/images/d399ca1d-3f3b-4474-ad46-b0aa17eb0459.png) **2. Versuch** ~~~ pdftotext -nopgbrk datei.pdf datei.zeilen.txt ~~~ [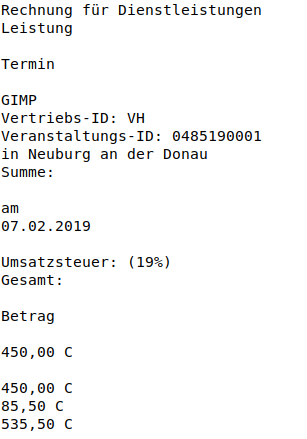](/images/4d26af03-35f3-43cd-9824-120aca7260ee.png)
Lösungsalternative: pdftotext bearbeitet von ursus contionabundo 09.02.2019 09:21 > Sämtliche Versuche, das PDF zu konvertieren, generieren noch viel mehr Datenmüll. Ich sags mal so: Wenn das PDF **generiert** (nicht mit einem Treiber als Grafik pder Postscript/PS gedruckt oder vom Faxserver aus einem Tiff umgewandelt wurde ) wurde, unverschlüsselt ist **und Tabellen enthält**, dann habe ich mit [pdftotex](https://linux.die.net/man/1/pdftotext) gute Erfahrungen gemacht. **1. Versuch** ~~~ pdftotext -nopgbrk -layout datei.pdf datei.layout.txt ~~~ [](/images/d399ca1d-3f3b-4474-ad46-b0aa17eb0459.png) **2. Versuch** ~~~ pdftotext -nopgbrk datei.pdf datei.zeilen.txt ~~~ [](/images/4d26af03-35f3-43cd-9824-120aca7260ee.png)
Lösungsalternative: pdftotext bearbeitet von ursus contionabundo 09.02.2019 09:20 > Sämtliche Versuche, das PDF zu konvertieren, generieren noch viel mehr Datenmüll. Ich sags mal so: Wenn das PDF **generiert** (nicht mit einem Treiber als Grafik gedruckt oder vom Faxserver aus einem Tiff umgewandelt wurde ) wurde **und Tabellen enthält**, dann habe ich mit [pdftotex](https://linux.die.net/man/1/pdftotext) gute Erfahrungen gemacht. **1. Versuch** ~~~ pdftotext -nopgbrk -layout datei.pdf datei.layout.txt ~~~ [](/images/d399ca1d-3f3b-4474-ad46-b0aa17eb0459.png) **2. Versuch** ~~~ pdftotext -nopgbrk datei.pdf datei.zeilen.txt ~~~ [](/images/4d26af03-35f3-43cd-9824-120aca7260ee.png)
Diese Zeile krieg ich nicht gematcht bearbeitet von ursus contionabundo 09.02.2019 09:10 > Sämtliche Versuche, das PDF zu konvertieren, generieren noch viel mehr Datenmüll. Ich sags mal so: Wenn das PDF **generiert** (nicht mit einem Treiber als Grafik gedruckt oder vom Faxserver aus einem Tiff umgewandelt wurde ) wurde **und Tabellen enthält**, dann habe ich mit [pdftotex](https://linux.die.net/man/1/pdftotext) gute Erfahrungen gemacht. **1. Versuch** ~~~ pdftotext -nopgbrk -layout datei.pdf datei.layout.txt ~~~ [](/images/d399ca1d-3f3b-4474-ad46-b0aa17eb0459.png) **2. Versuch** ~~~ pdftotext -nopgbrk datei.pdf datei.zeilen.txt ~~~ [](/images/4d26af03-35f3-43cd-9824-120aca7260ee.png)
Diese Zeile krieg ich nicht gematcht bearbeitet von ursus contionabundo 09.02.2019 09:09 > Sämtliche Versuche, das PDF zu konvertieren, generieren noch viel mehr Datenmüll. Ich sags mal so: Wenn das PDF **generiert** (nicht mit einem Treiber als Grafik gedruckt oder vom Faxserver aus einem Tiff umgewandelt wurde ) wurde **und Tabellen enthält**, dann habe ich mit [pdftotex](https://linux.die.net/man/1/pdftotext) gute Erfahrungen gemacht. ~~~ pdftotext -nopgbrk -layout datei.pdf datei.layout.txt ~~~ [](/images/d399ca1d-3f3b-4474-ad46-b0aa17eb0459.png) pdftotext -nopgbrk datei.pdf datei.zeilen.txt ~~~ [](/images/4d26af03-35f3-43cd-9824-120aca7260ee.png)
Diese Zeile krieg ich nicht gematcht bearbeitet von ursus contionabundo 09.02.2019 09:08 > Sämtliche Versuche, das PDF zu konvertieren, generieren noch viel mehr Datenmüll. Ich sags mal so: Wenn das PDF **generiert** (nicht mit einem Treiber als Grafik gedruckt oder vom Faxserver aus einem Tiff umgewandelt wurde ) wurde **und Tabellen enthält**, dann habe ich mit [pdftotex](https://linux.die.net/man/1/pdftotext) gute Erfahrungen gemacht. ~~~ pdftotext -nopgbrk -layout datei.pdf datei.layout.txt pdftotext -nopgbrk datei.pdf datei.zeilen.txt ~~~
 nicht angemeldet
nicht angemeldet

