Ich denke, dein Code ist nicht sehr robust. Und schwer lesbar finde ich ihn auch.
Ich tät's so aufschreiben:
while ( ($chckdIid = fgets($oldFile)) !== false ) {
if (substr($chckdIid, 1) === $ChangeOnId) {
$chckdIid = ($chckdIid[0] === "0" ? "7" : "0") . $ChangeOnId
}
fwrite($file, $chckdIid);
}
Und zwar aus diesen - möglicherweise subjektiven - Gründen:
fgets liefert false, wenn EOF erreicht ist. Es gibt aber auch noch andere Werte, die falsy sind, wie z.B. Leerstring oder der String "0". Das wird Dir bei fgets (glaube ich) nicht passieren, aber ich finde, man sollte sich gerade bei diesem Designirrtum namens PHP API nicht auf truthy oder falsy verlassen, sondern explizit auf false abfragen.
Vergleich mit == führen in PHP erstmal zum Versuch, die Typen anzugleichen. Wenn das nicht nötig ist, oder ggf schädlich sein könnte, nehme ich immer === und !==, die setzen Typgleichheit voraus.
Auf eine Stelle eines Strings muss man übrigens nicht mit substr zugreifen, da geht auch []. Einen Fehler wegen Indexzugriff hinter's Stringende kannst Du in diesem Fall nicht bekommen, weil sonst vorher schon der Vergleich mit $ChangeOnId falsch ist.
Die Bitmanipulation, um zwischen 0 und 7 umzuschalten, sieht nach einer cleveren Lösung aus, ich halte es aber für eine nicht empfehlenswerte Praxis, die numerische Codierung eines Zeichens ohne Not als bekannt vorauszusetzen. Und er muss dafür unter der Haube eben mal zwischen String -> Int -> String hin und her jonglieren.
Rolf
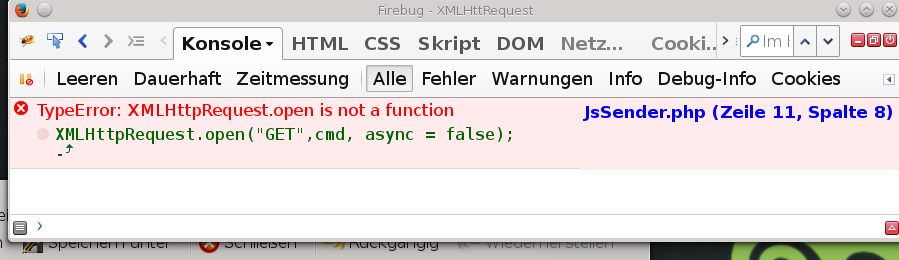
Nachtrag: Warum machst Du das eigentlich mit window.open()? Du kannst ein PHP Script auch als XMLHttpRequest aufrufen, also Ajax. Da brauchst Du dich nicht einmal auf die Antwort zu registrieren, die interessiert Dich sowieso nicht. Spricht da was gegen?



 dedlfix
dedlfix
 Rolf b
Rolf b
Tabellenkalk
 Matthias Apsel
Matthias Apsel