 nicht angemeldet
nicht angemeldet


@@Auge,
- Eigentlich müsste man alle Seiten, deren Crawling in der robots.txt verboten wird, mit dem <meta>-Tag noindex kennzeichnen, nur so kann man vermeiden, dass in den Google SERPS Ergebnisse angezeigt werden, bei welchen keine Meta Description ausgelesen werden kann. In der Praxis geht das aber nicht, weil:
Die Anweisung noindex funktioniert nur, wenn die Seite nicht durch eine robots.txt-Datei blockiert wird.
Was lässt dich das vermuten?
Dieser Google Hilfe Artikel:
https://support.google.com/webmasters/answer/93710?hl=de
Im Artikel steht folgendes:
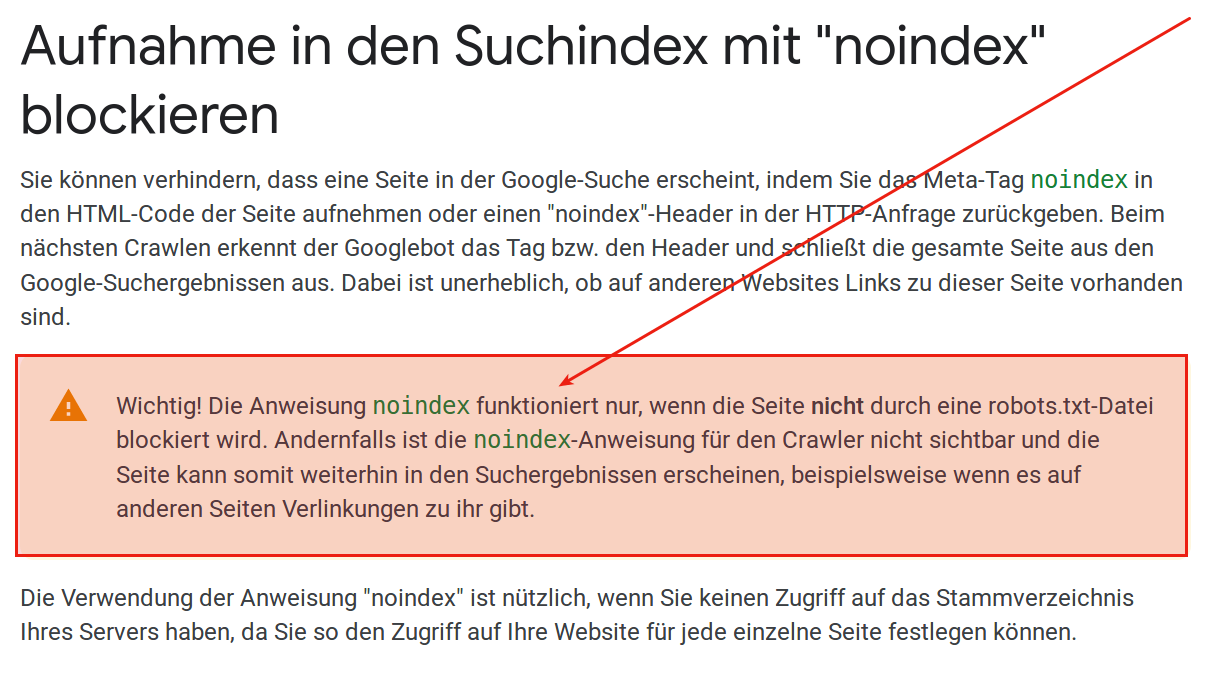
Wenn ein Bot die in der robots.txt festgelegten Regeln strikt befolgt, indexiert er Seiten in den angegebenen Verzeichnissen per se nicht.
Doch, wenn die Seite Backlinks hat schon, dann wird die Seite indexiert aber nicht gecrawlt.
Also gäbe es keinen Grund für
meta noindex.
Doch, den gäbe es. Ich möchte kein solches Ergebnis in den SERPS:
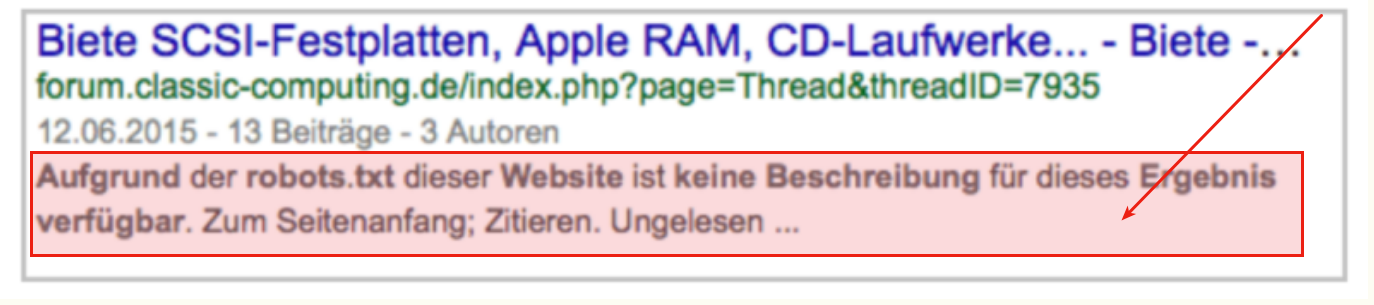
Indexiert er sie entgegen dem in der robots.txt geäußerten Wunsch aber doch, dann wird er auch das
meta noindexfinden.
Eben nicht, sonst dürfte es so etwas wie im Screenshot oben nicht geben.
In der robots.txt sage ich ausschließlich das die Seiten nicht gecrawlt werden sollen. In der robots.txt kann ich nicht sagen, dass die Seiten nicht indexiert werden sollen. Das sind zwei paar Schuhe.
Wenn er aber das Meta-Element findet, gibt es keinen Grund, die dort festgelegte Regel nicht zu befolgen, außer er ignoriert eine solche Regel sowieso.
Laut dem oben verlinkten Google Artikel wird er das Meta-Element nicht finden, wenn ein disallow in der robots.txt ist. Was nicht gefunden wird kann auch nicht befolgt werden.
 Auge
Auge