Hallo
das Crawling Budget des Google Bots pro Webseite ist ja begrenzt.
User-agent: *
Disallow: /admin/
Disallow: /core/
Disallow: /tmp/
Disallow: /views/
Disallow: /setup/
Disallow: /log/
Disallow: /*?cl=search
Disallow: /*&cl=search
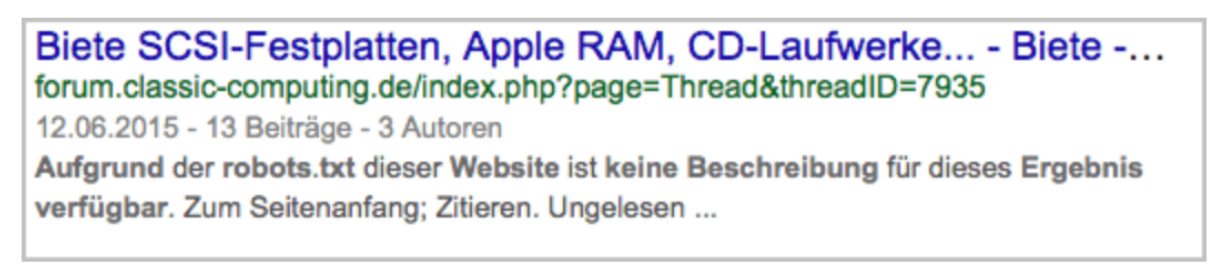
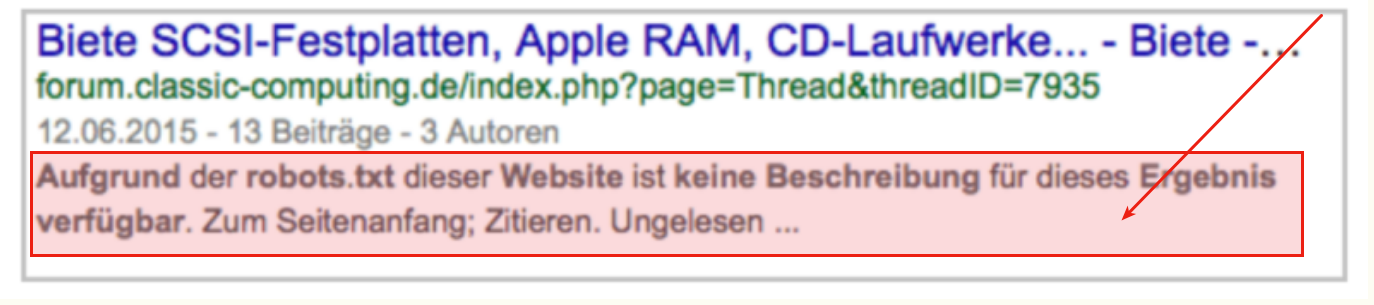
Wird […] eine Seite, aus den oben genannten Verzeichnissen verlinkt, so kann es trotzdem sein, dass diese Seite im Google Index auftaucht. Die Meta Description kann allerdings nicht ausgelesen werden, da ein Crawling in der robots.txt verboten wurde.
Nur mal als Klarstellung. Mit der robots.txt verbietest du sage und schreibe nichts. Die Befolgung der Anweisungen in der robots.txt ist freiwillig. (Nicht nur) Google richtet sich nach den Anweisungen, aber damit entspricht Google irgendwie einem geäußerten Wunsch, befolgt aber nicht ein Verbot (auch wenn da Disallow steht).
Fragen:
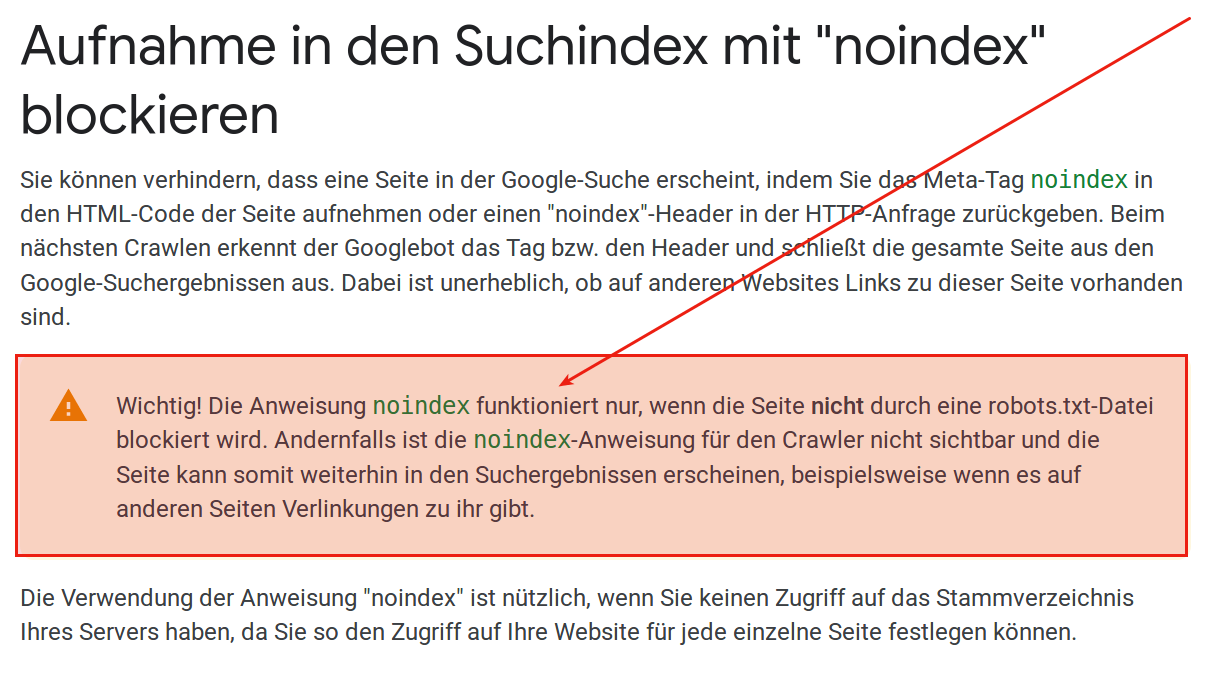
- Eigentlich müsste man alle Seiten, deren Crawling in der robots.txt verboten wird, mit dem <meta>-Tag noindex kennzeichnen, nur so kann man vermeiden, dass in den Google SERPS Ergebnisse angezeigt werden, bei welchen keine Meta Description ausgelesen werden kann. In der Praxis geht das aber nicht, weil:
Die Anweisung noindex funktioniert nur, wenn die Seite nicht durch eine robots.txt-Datei blockiert wird.
Was lässt dich das vermuten? Wenn ein Bot die in der robots.txt festgelegten Regeln strikt befolgt, indexiert er Seiten in den angegebenen Verzeichnissen per se nicht. Also gäbe es keinen Grund für meta noindex. Indexiert er sie entgegen dem in der robots.txt geäußerten Wunsch aber doch, dann wird er auch das meta noindex finden. Wenn er aber das Meta-Element findet, gibt es keinen Grund, die dort festgelegte Regel nicht zu befolgen, außer er ignoriert eine solche Regel sowieso.
-
Angenommen man kennzeichnet eine Seite mit dem <mata>-Tag noindex. Dann wird die Seite zwar nicht indexiert Crawling Budget wird aber schon verbraucht oder?
-
Wie kann ich erreichen, dass eine Seite weder gecrawlt wird und damit keine Crawling Budget verbraucht noch indexiert wird? Ist das in Kombination überhaupt möglich?
Du bist darauf angewiesen, dass ein Suchmaschinenroboterbetreiber die auf einer Website angegebenen Regeln befolgt. Du hast als Werkzeuge innerhalb deiner Website dazu die robots.txt, Meta-Angaben im Dokumentkopf und zuguter Letzt noch das Attruíbut rel mit dem Wert "nofollow" in Links, denen ein Robot nicht folgen soll (nicht "nicht darf").
Tschö, Auge
--
Eine Kerze stand [auf dem Abort] bereit, und der Almanach des vergangenen Jahres hing an einer Schnur. Die Herausgeber kannten ihre Leser und druckten den Almanach auf weiches, dünnes Papier.
Kleine freie Männer von Terry Pratchett
 nicht angemeldet
nicht angemeldet


 Auge
Auge