 nicht angemeldet
nicht angemeldet


 Auge
AugeHallo
Die Anweisung noindex funktioniert nur, wenn die Seite nicht durch eine robots.txt-Datei blockiert wird.
Was lässt dich das vermuten?
Dieser Google Hilfe Artikel:
https://support.google.com/webmasters/answer/93710?hl=de
Im Artikel steht folgendes:
Laut dem oben verlinkten Google Artikel wird er das Meta-Element nicht finden, was nicht gefunden wird kann auch nicht befolgt werden.
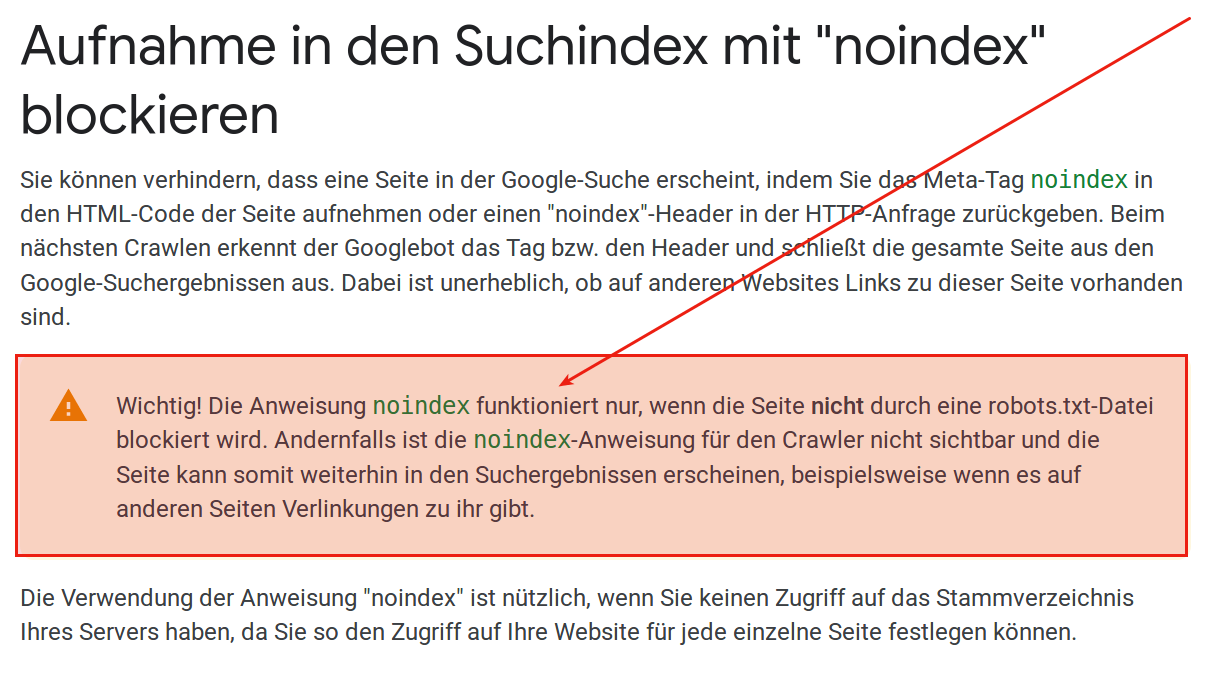
Dann muss ich also davon ausgehen, dass Google entgegen eigener Aussagen die in der robots.txt festgelegten Regeln nicht (vollständig) befolgt.
Wenn ein Verzeichnis per robots.txt von der Indexierung durch Suchroboter ausgeschlossen werden soll, aber nach Bekanntmachung dieses Wunsches per robots.txt dennoch Suchergebnisse für die Seite vorliegen, folgt der betreffende Suchmaschinenroboter dem Wunsch nicht. Denn dann sollte er bei Kenntnis der Regeln der robots.txt betreffende Seiten auch dann nicht indexieren, wenn sie von anderen Seiten (zumindest der selben Domain) aus verlinkt sind.
Wenn Google selbst schreibt „die Seite kann […] in den Suchergebnissen erscheinen, beispielsweise wenn es auf anderen Seiten Verlinkungen zu ihr gibt.“, dann sollte man überlegen, die Links, wenn es geht, zu entfernen oder ihnen das Attribut rel hinzuzufügen. Das hilft natürlich nur bei Links, deren Generierung man selbst unter Kontrolle hat. Bei Links von fremden Seiten hat man das natürlich nicht. Ansonsten wäre zu überlegen, das Verzeichnis für die betreffenden Seiten aus dem Regelsatz der robots.txt zu entfernen und die Indexierung über einen HTTP-Header und zusätzlich mit dem passenden Meta-Element zu unterbinden.
Tschö, Auge
Eine Kerze stand [auf dem Abort] bereit, und der Almanach des vergangenen Jahres hing an einer Schnur. Die Herausgeber kannten ihre Leser und druckten den Almanach auf weiches, dünnes Papier.
Kleine freie Männer von Terry Pratchett