Tach!
Mit ajax oder fetch hat das gar nichs zu tun. Das BOM wird von split entfernt, Code zum testen:
Auch ich habe das bei mir so gesehen, dass nach einem Ajax-Request keine BOM am Anfang der Daten mehr enthalten war. Dazu habe ich deinen Code genommen und die wahlkreise.csv um eine BOM erweitert. Sie war ja ohne. Überprüft habe ich die Datei mit einem Hexdump, die BOM und Umlaute waren da und UTF-8-kodiert. Nach dem Ajax-Request war das Zeichen charCodeAt(0) bereits keine BOM mehr. Deswegen habe ich dich ja aufgefordert, den String nach dem Ajax-Request und vor dem split() zu überprüfen.
function getbom(){
var str = "\uFEFF"+"a;b"+"\uFEFF";
var ab = str.split(";");
var bb = new Blob([str]);
console.log( "Länge String mit BOM: "+bb.size+" bytes\n", ab );
}
und hier die DEMO, Console gucken:
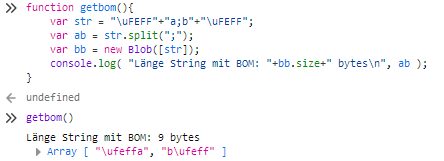
Länge String mit BOM: 9 bytes
Array [ "a", "b" ]
Die BOM wird sowohl am Anfang als auch am Ende entfernt.
Ist vielleicht immer noch einfach nur dein Firefox zu alt? Jedenfalls prüfst du hier nur die Länge des zum Blob gewandelten String vor dem split() einerseits und siehst das was dir die Console andererseits anzeigt. Es wäre sinnvoll, die beiden Teilstrings in ab genauer zu untersuchen.
Bei mir im aktuellen Firefox sieht das Ergebnis jedenfalls so aus.
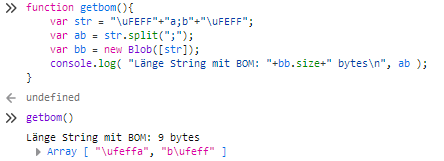
Beide BOMs sind noch vorhanden. Ich erweitere mal deine Codevorlage, so dass ich von den beiden Teilstrings sowohl die Länge in Zeichen als auch die Codepoints der Zeichen ausgebe.
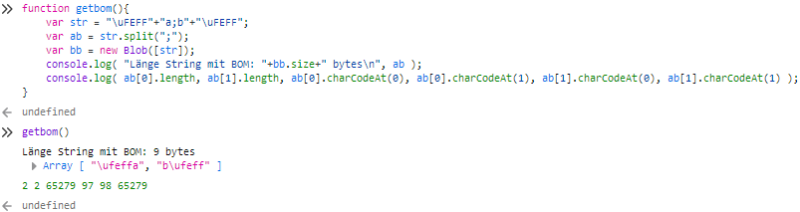
Ich sehe da also eine Länge von jeweils zwei Zeichen und die vorhandenen BOMs.
Die BOM wird mir allerdings nicht angezeigt, wenn ich die Strings mit alert(ab[0]) ausgebe oder direkt in console.log(ab[0]) als String anstatt in einem Array. Das ist aber nur ein Problem der Anzeige, denn mit charCodeAt() lässt sich nach wie vor prüfen, dass die Zeichen da sind.
Der Chrome hingegen zeigt die BOMs auch bei Strings innerhalb eines Arrays nicht an. Aber auch hier lässt sich mit length und charCodeAt() die Existenz nachweisen.
dedlfix.



 Linuchs
Linuchs
 dedlfix
dedlfix
 Der Martin
Der Martin
 Rolf B
Rolf B Matthias Apsel
Matthias Apsel und die BOM")
 mit BOM in der Mitte")