


Flaschenhals bei Query finden (mysql(i))
Jörg
- sql
 nicht angemeldet
nicht angemeldetHallo,
ich habe eine Query, die mir eine wunderbare Ergebnismenge produziert, aber ewig lange dauert, wenn die Datenmenge etwas größer ist. Und mit etwas größer meine ich nicht wirklich richtig groß, es reichen schon ein paar 10.000 Einträge der Haupttabelle nebst ähnlich vielen Einträgen der abhängigen Tabellen.
Die Query:
SELECT SQL_CALC_FOUND_ROWS DISTINCT
r.KundenID,
...,
...,
ze.bezahlt,
da.ListenID,
ADDDATE(
r.Rechnungsdatum,
INTERVAL r.Faelligkeit DAY
),
m.Mahnstatus,
ADDDATE(
m.Mahndatum,
INTERVAL m.Faelligkeit DAY
),
UNIX_TIMESTAMP(
ADDDATE(
r.Rechnungsdatum,
INTERVAL r.Faelligkeit DAY
)
),
UNIX_TIMESTAMP(
ADDDATE(
m.Mahndatum,
INTERVAL m.Faelligkeit DAY
)
),
CASE WHEN(r.bezahlt = 1) THEN 'A' WHEN(r.Storno = 1) THEN 'A' WHEN(r.Druck = 0) THEN 'A' ELSE DATEDIFF(
CURDATE(), ADDDATE(
r.Rechnungsdatum,
INTERVAL r.Faelligkeit DAY
))
END,
k.del,
(
SELECT
SUM(ze.Bruttozahlung)
FROM
tableprefix_zahlungseingang ze
WHERE
ze.RechnungenID = r.RechnungenID
) AS BruttoSumme,
rz.GesamtRetoure
FROM
tableprefix_rechnungen r
LEFT JOIN tableprefix_rechnungszuordnung rz ON
r.RechnungenID = rz.RechnungenID
LEFT JOIN tableprefix_zahlungseingang ze ON
r.RechnungenID = ze.RechnungenID
LEFT JOIN tableprefix_datev_belege da ON
da.BelegID = r.RechnungenID
LEFT JOIN tableprefix_berechnungen b ON
r.RechnungenID = b.RechnungenID
LEFT JOIN tableprefix_mahnungen m ON
(
r.RechnungenID = m.RechnungenID AND m.aktiv = 1
) AND m.Mahnstatus =(
SELECT
MAX(tmp.Mahnstatus)
FROM
tableprefix_mahnungen tmp
WHERE
tmp.RechnungenID = r.RechnungenID AND tmp.aktiv = 1
)
LEFT JOIN tableprefix_kunden k ON
r.KundenID = k.KundenID
WHERE
r.Belegart = "RG"
GROUP BY
r.RechnungsNummer
ORDER BY
r.RechnungenID
Ein Explain ergibt:
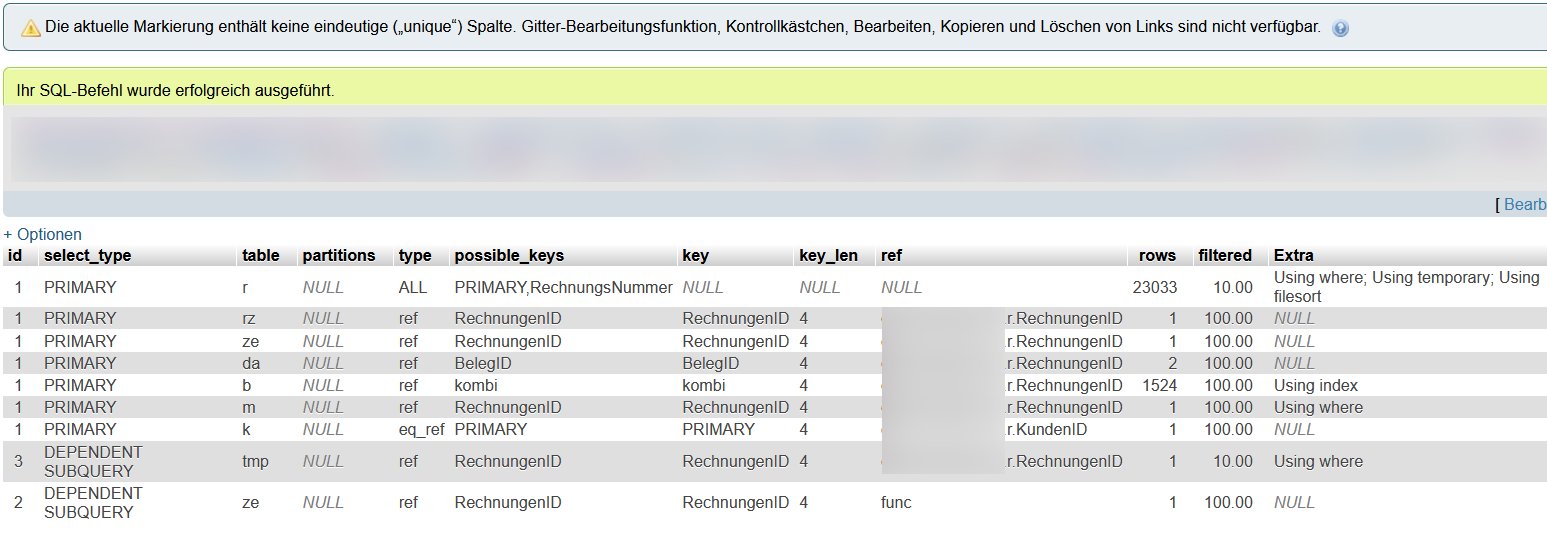
Leider weiß ich die Auswertung nicht wirklich zu deuten. Die Query benötigt aber 8-10 Sekunden, das ist eindeutig zu lang, da ist also wirklich ein fehlender Index oder Ähnliches die Ursache, scheint mir.
Wäre für hilfreiche Tips dankbar.
Guten Start ins WE, Jörg
Hallo Jörg,
mir ist schlecht. Was für eine Höllenquery. Aus vielen Gründen...
(1) Du verwendest einen GROUP BY RechnungsNummer. Der sorgt dafür, dass dein Output zu jeder Rechnungsnummer genau eine Row enthält. Zusätzlich hast Du einen DISTINCT drin. Der sorgt dafür, dass dein Ergebnis keine Duplikate enthält. Es ist nun relativ egal, ob der DISTINCT vor oder nach der Gruppierung ausgeführt wird, aber solange Du zum GROUP BY keine Aggregierungsfunktionen verwendest, ist das Ergebnis mit und ohne DISTINCT das Gleiche. Er kostet aber einen Durchlauf durch die Daten, um Duplikate zu ermitteln.
(2) Ich hab Dir das sicherlich schon mehrfach erklärt. GROUP BY verlangt, dass jede Spalte, die nicht zum Gruppieren genutzt wird, aggregiert werden muss. Die große Macke von MYSQL ist, dass es das nicht erzwingt. Statt dessen benutzt es einfach irgendeinen Satz aus der Gruppe. Soweit ich weiß ist das der, den es beim Gruppieren zuerst antrifft. Ob das der richtige ist, hängt von der Anordnung der Daten in den Tabellen ab (d.h. unter anderem vom clustering index).
Brauchst Du den GROUP BY? Hat deine Rechnungen-Tabelle zu einer Rechnungsnummer mehrere Rows? Wenn ja: Was ist dann mit den anderen r-Spalten, die Du nutzt? Haben die für eine Rechnungsnummer alle den gleichen Wert? Hier ist entweder eine Quelle für falsche Datenauswahl, oder ein Indiz für einen groben Normalisierungsfehler.
Das ist kein Kritteln neben dem Thema. Ein GROUP BY kann Aufwand kosten, der ggf. nicht nötig ist.
(3) Ich würde auch gerne wissen, was aus dem Rows=2 bei den Datevbelegen zu deuten ist. Gibt es zu einer RechnungenID unterschiedliche ListenIDs in der Datevbelete-Tabelle?
(4) Du verwendest SQL_CALC_FOUND_ROWS. Warum? Du hast keine LIMIT Klausel drin. SQL_CALC_FOUND_ROWS ist interessant für eine paginierte Ansicht, bei der man die Gesamtzahl der Zeilen wissen möchte, um sowas wie "Seite drölf von umpfzig" ausgeben zu können. Hier steht eine Info der MYSQL Entwickler zu dieser Option, sie soll abgeschafft werden. Unter anderem, weil sie langsam ist. Brauchst Du SQL_CALC_FOUND_ROWS für eine nachfolgenden SELECT FOUND_ROWS()? Wenn nicht, weg damit, diese Klausel hat keine andere Existenzberechtigung. Und wenn Du diesen SELECT machst - warum? Ohne LIMIT ist er sinnlos, du liest die Rows alle nach PHP und kannst sie dabei zählen.
(5) Als nächstes sehe ich da den Datev-Join. Wie ist dein Mengengerüst? Kann es für eine RechnungenID tatsächlich mehrere unterschiedliche ListenIDs geben? Ist das fachlich so? Dem Explain sehe ich das nicht an und deine Daten kenne ich nicht.
(6) Wozu joinst Du die Berechnungen? Du machst dem Anschein nichts damit. Vermutlich steckt das im "..." Bereich. Im Explain steht 1524 Rows. Wieviele Rows hat die Berechnungen-Tabelle, wieviele Rows pro RechnungenID? Kann diese 1524 deine Datenmenge interimsmäßig explodieren lassen? Der GROUP BY würde sie wieder eindampfen, auf eine Row für eine Rechnungsnummer, aber was ist dann der Zweck des Ganzen?
Ob sich noch mehr tun lässt, hängst jetzt auch von deinen Antworten ab…
Rolf
Hallo Rolf,
vorab vielen Dank für Deine Hilfe. Vielen Dank auch für Deine späte Nachricht gestern abend noch. Ich habe die noch spät in der Nacht gelesen und konnte schon gedanklich "damit arbeiten", auch wenn ich erst heute morgen antworte.
Jetzt muss ich nur versuchen, Dir auf Deine Fragen zu antworten, von denen mir noch nicht alle ganz klar sind. Aber der Reihe nach...
Zuerstmal meine "..." in der Query, da habe ich nur zusätzliche Spalten mit dem Alias "r" herausgenommen, also fehlt da inhaltlich nichts zur Query. Dann habe ich zusätzlich noch meine LIMIT-Angaben herausgenommen. Das erklärt dann auch mein SQL_CALC_FOUND_ROWS.
(1) Du verwendest einen GROUP BY RechnungsNummer. Der sorgt dafür, dass dein Output zu jeder Rechnungsnummer genau eine Row enthält. Zusätzlich hast Du einen DISTINCT drin. Der sorgt dafür, dass dein Ergebnis keine Duplikate enthält. Es ist nun relativ egal, ob der DISTINCT vor oder nach der Gruppierung ausgeführt wird, aber solange Du zum GROUP BY keine Aggregierungsfunktionen verwendest, ist das Ergebnis mit und ohne DISTINCT das Gleiche. Er kostet aber einen Durchlauf durch die Daten, um Duplikate zu ermitteln.
Ok. Das Weglassen des "DISTINCTS" habe ich mal ausprobiert, das hat aber keinen merklichen zeitlichen Vorteil gebracht.
(2) Ich hab Dir das sicherlich schon mehrfach erklärt. GROUP BY verlangt, dass jede Spalte, die nicht zum Gruppieren genutzt wird, aggregiert werden muss.
Möglicherweise hast Du das. Vielleicht hab ichs einfach nochn nicht kapiert, was das genau heißt. Kannst Du mir das nochmal an einem Beispiel klar machen?
Brauchst Du den GROUP BY? Hat deine Rechnungen-Tabelle zu einer Rechnungsnummer mehrere Rows?
Hmm. Die Rechnungstabelle selber hat zu jeder Rechnungsnummer genau eine einzige Zeile.
Es kann zu jeder Rechnungsnummer natürlich aus anderen Tabellen mehrere Einträge geben, so können natürlich mehrere Zahlungseingänge o.ä. zu einer Rechnungsnummer vorhanden sein, aber die Rechnungentabelle hat nur 1 Zeile je Rechnungsnummer.
Das ist kein Kritteln neben dem Thema. Ein GROUP BY kann Aufwand kosten, der ggf. nicht nötig ist.
Ja ok, so verstehe ich das auch.👍
(3) Ich würde auch gerne wissen, was aus dem Rows=2 bei den Datevbelegen zu deuten ist. Gibt es zu einer RechnungenID unterschiedliche ListenIDs in der Datevbelete-Tabelle?
Es gibt zu jeder RechnungenID mindestens einen, meist aber 2 Datevbelege, nämlich einmal den RG-Betrag und einmal die UsT (falls angefallen). Unterschiedliche ListenIDs zu einer RG sollte es nicht geben. Die ListenID steht für die Liste, die der User (meist monatlich) für den Datevexport generiert.
(4) Du verwendest SQL_CALC_FOUND_ROWS. Warum? Du hast keine LIMIT Klausel drin. SQL_CALC_FOUND_ROWS ist interessant für eine paginierte Ansicht, bei der man die Gesamtzahl der Zeilen wissen möchte, um sowas wie "Seite drölf von umpfzig" ausgeben zu können.
Sorry, ich hatte das LIMIT herausgenommen, genau dafür verwende ich SQL_CALC_FOUND_ROWS.
(5) Als nächstes sehe ich da den Datev-Join. Wie ist dein Mengengerüst? Kann es für eine RechnungenID tatsächlich mehrere unterschiedliche ListenIDs geben? Ist das fachlich so? Dem Explain sehe ich das nicht an und deine Daten kenne ich nicht.
Beantwortet meine Antwort zu Punkt 3 diese Frage oder soll ich nochmal etwas genauer erklären? Rein von der Logik her würde ich behaupten, dass für eine RechnungenID überhaupt keine unterschiedlichen ListenbIDs existieren dürfen. Selbst wenn ich eine RG schreibe, sie im nächsten monat gutschreibe und wieder inen Monat später neu berechne, ist das nicht so. Denn dann erhält sowohl die Gutschrift als auch die neue RG jeweils eine neue RechnungenID (GU und RG sind bei mir beides "Rechnungen", daher erhält auch die GU eine RechnungenID.
(6) Wozu joinst Du die Berechnungen? Du machst dem Anschein nichts damit. Vermutlich steckt das im "..." Bereich. Im Explain steht 1524 Rows. Wieviele Rows hat die Berechnungen-Tabelle, wieviele Rows pro RechnungenID? Kann diese 1524 deine Datenmenge interimsmäßig explodieren lassen? Der GROUP BY würde sie wieder eindampfen, auf eine Row für eine Rechnungsnummer, aber was ist dann der Zweck des Ganzen?
Oh. Womöglich habe ich in der Vergangenheit mal was damit gemacht, was dann später wieder entfiel? Keine Ahnung. Aber ein Wegnehmen dieses JOINS bringt tatsächlich schonmal Einiges. Im Test (ok, solche Tests sind nicht ganz zuverlässig, ich weiß...) konnte ich die Durchlaufzeit der Query jedenfalls durch Weglassen dieses JOINS schonmal erheblich (auch 40%) reduzieren.
Ob sich noch mehr tun lässt, hängst jetzt auch von deinen Antworten ab…
Hoffe, da ist noch etwas Brauchbares dabei. Ansonsten bitte nochmal nachfragen, jedenfalls vielen lieben Dank für die Hilfe!! 👍
Jörg
Hallo Jörg,
danke für die Rückmeldung. Damit kann ich arbeiten 😂
Wie verlinkt - das Ding ist langsam. Es wird gesagt, dass es günstiger sei, die Query ohne SQL_CALC_FOUND_ROWS durchzuführen, und die Anzahl der Zeilen mit einem SELECT COUNT(*) separat zu ermitteln. Weil der Server dann COUNT-Optimierungen nutzen könnte. Das ist in deinem Fall besonders deutlich, weil bei Dir die Anzahl der Ergebniszeilen durch die Anzahl der gefundenen Rechnungsnummern mit Belegart 'RG' bestimmt wird. Du kannst an Stelle des separaten SELECT FOUND_ROWS(), mit dem Du das Ergebnis des SQL_CALC_FOUND_ROWS abholen müsstest, alle JOINS und Subselects weglassen und einfach
SELECT COUNT(*) FROM rechnungen WHERE belegart = 'RG'
machen. Das sollte in Summe schneller sein.
Wenn Du eine LIMIT Verarbeitung machst, weil Du das Ergebnis durchblättern willst, könnte es auch helfen (weiß ich aber nicht - MYSQL optimiert LIMIT Angaben ziemlich gut), wenn Du in einer ersten Query die zu zeigenden RechnungsIDs bestimmst. Da es zu einer Rechnungsnummer immer nur einen Satz gibt, sollte sich das allein mit der Rechnungen-Tabelle ausführen lassen. Für die Monsterquery fügst Du in der WHERE-Klausel noch ein "AND RechnungenID IN ($idlist)" hinzu. $idlist ist eine kommaseparierte Implosion der IDs aus der ersten Query. Du solltest aber im PHPMYADMIN erstmal manuell versuchen, ob das überhaupt merklich was bringt. Versuche unterschiedliche ID-Bereiche einmal mittels LIMIT und einmal mittels IN Auflistung zu selektieren und vergleiche die Laufzeit.
Ein Beispiel - bei Dir ggf. so nicht relevant. Es soll das GROUP BY Thema klarstellen
Tabelle 1 (Rechnungen)
RechnungID Nummer Betrag
1 17 12,10
2 37 13,25
3 97 22,50
Tabelle 2 (Berechnungen)
BelegID Datum Typ Ergebnis
1 01.01.2021 XY 1234
1 11.01.2021 XZ 4711
2 05.01.2022 QI 815
Nun machst Du
SELECT Nummer, Betrag, Datum, Ergebnis
FROM rechnungen r
LEFT JOIN berechnungen b ON r.RechnungID = b.BelegID
GROUP BY Nummer
Die temporäre Ergebnistabelle vor dem GROUP BY sieht so aus
Nummer Betrag Datum Ergebnis
17 12,10 01.01.2021 1234
17 12,10 11.01.2021 4711
37 13,25 05.01.2022 815
97 22,50 NULL NULL
Und dein SQL Server steht nun beim Gruppieren vor einer Entscheidung, die er nicht treffen kann. Welchen Betrag, welches Datum und welches Ergebnis soll er für Nummer 17 wählen? Das ist durch die Query nicht festgelegt. Deswegen ist das bei den meisten SQL Systemen ein Fehler. Du musst eine Aggregierungsfunktion verwenden (COUNT, MIN, MAX, SUM, AVG). Beim Betrag ist die Entscheidung treffbar, aber SQL lässt sich auf diesen Sonderfall gar nicht ein. Was im GROUP BY steht, wird nicht aggregiert und was nicht im GROUP BY steht, muss aggregiert werden.
MYSQL ignoriert dieses Entscheidungsproblem, indem es einfach den ersten Satz der Gruppe verwendet.
Bei Dir ist es so, sagst Du, dass die Rechnungentabelle zu jeder Nummer genau einen Satz enthält und eine Mehrdeutigkeit nur durch die Joins entstehen kann. Gucken wir uns das im Licht des Explains nochmal an.
Der Explain sagt eigentlich überall "Rows=1" - außer bei der Datev und bei den Berechnungen. Die Mehrdeutigkeit kommt also nur von dort.
Du schreibst, es könnte mehrere Zahlungseingänge zu einer Rechnung geben. Was hat es denn dann mit der Spalte ze.bezahlt auf sich? Hier kommt wieder der GROUP BY Konflikt ins Spiel. Wenn es 3 Zahlungseingänge gibt und nicht alle den gleichen Wert für "bezahlt" haben - welcher dieser Werte gehört dann ins Ergebnis? Was sagt "bezahlt" bei den Zahlungseingängen überhaupt aus?
Bei der Datev kann man es mit einem Subselect lösen. Schreibe statt da.ListenID einfach dies in die Spaltenliste des SELECT - ähnlich wie bei den Bruttozahlungen:
(SELECT ListenID FROM daten_belege
WHERE belegID=r.rechnungenID LIMIT 1) AS ListenID,
Dieses AS ListenID hintendran gibt der berechneten Spalte einen Namen. Machst Du bei der Bruttosumme ja auch. Das solltest Du auch bei den berechneten Timestamps machen, PHP Code ist besser wartbar, wenn er mit Spaltennamen statt Spaltennummern arbeitet.
Was es mit den Berechnungen auf sich hat - tja. War ja offenbar ein unnötiger JOIN 😂, den zu streichen ist die beste Optimierung.
Wenn Du nur noch Einzelsätze hinzujoinst, sollte sich der GROUP BY erledigt haben. Dafür muss allerdings zuerst geklärt werden, wie mit der Spalte ze.bezahlt bei mehreren Zahlungseingängen umzugehen ist.
Die Eindeutigkeit kannst Du dann im phpMyAdmin validieren, indem Du zwischen GROUP BY Klausel und ORDER BY Klausel ein
HAVING COUNT(*) > 1
einfügst. Natürlich nicht in der PHP Anwendung. Die HAVING-Klausel ist sozusagen ein zusätzliches WHERE, das nach dem GROUP BY ausgeführt wird. Der Gezeigte HAVING liefert Dir alle Rechnungsnummern, für die es vor dem GROUP BY mehr als einen Satz gab.
Rolf
Hallo Rolf,
ich muss gerade mal eine Zwischenantwort schreiben. Eigentlich viel zu früh, weil ich Deine Antwort für mein Dafürhalten noch nicht intensiv genug durchgearbeitet habe. Es kommt also noch eine weitere Antwort.
Aber ich bin grad so überwältigt vom Ergebnis, das muss jetzt einfach sofort raus. 😅
Du weißt ja, dass das Weglassen des JOINS (berechnungen) bereits die Query auf irgendwas zwischen 25 und 40% der Ursprungsquery reduziert hatte. Fand ich schon wirklich klasse.
Aber jetzt kommts und das dürfte auch für dich interessant sein.
Wenn Du eine
LIMITVerarbeitung machst, weil Du das Ergebnis durchblättern willst, könnte es auch helfen (weiß ich aber nicht - MYSQL optimiert LIMIT Angaben ziemlich gut), wenn Du in einer ersten Query die zu zeigenden RechnungsIDs bestimmst. Da es zu einer Rechnungsnummer immer nur einen Satz gibt, sollte sich das allein mit der Rechnungen-Tabelle ausführen lassen. Für die Monsterquery fügst Du in der WHERE-Klausel noch ein "AND RechnungenID IN ($idlist)" hinzu. $idlist ist eine kommaseparierte Implosion der IDs aus der ersten Query. Du solltest aber im PHPMYADMIN erstmal manuell versuchen, ob das überhaupt merklich was bringt. Versuche unterschiedliche ID-Bereiche einmal mittels LIMIT und einmal mittels IN Auflistung zu selektieren und vergleiche die Laufzeit.
Das ist der absolute Hammer. 👍😍
Selbst wenn ich den unnötigen berechnungen-JOIN drin lasse, reduziert dieser Tip die Urspungsquery auf einen fast nicht messbaren (weil so kurz) Bruchteil der Usprungsquery und ich rede jetzt tatsächlich von "anstatt 8 Sekunden nun 0,0Irgendwas Sekunden Sekunden"
Habe jetzt so 4-5 Messungen gemacht und das ist so wirklich reproduzierbar.
Ich werde später den Rest Deines Posts auch noch durcharbeiten, aber ich glaube, neben dem Entfernen des unnötigen JOINS wird dann meine Hauptaufgabe sein, eine schlanke Query zu finden, die mir pro anzuzeigende Seite die entsprechende $idlist vorab selektiert. Oder wie siehst Du das?
Trotzdem interessiert mich, ob der GROUP BY nötig ist oder nicht. Das aber vorrangig, um es zu verstehen. Denn so etwas kommt ja "alle Nase lang" vor.
Wirklich mega, Deine Tips! 👍
Jörg
Hallo Jörg,
die entsprechende $idlist vorab selektiert. Oder wie siehst Du das?
Nein, andersrum. Das ist eine dritte Query und Du hast Aufwand, die $idlist zu erzeugen. Das ist aus meiner Sicht nur nötig, wenn die eingebauten LIMIT Optimierungen von MYSQL nicht reichen.
Ich denke aber, dass DISTINCT, GROUP BY und SQL_CALC_FOUND_ROWS genau diese Optimierungen aushebeln und die Query langsam machen. Erster Versuch sollte deshalb sein, den GROUP BY und das SQL_CALC_FOUND_ROWS wegzubekommen. Soweit ich Dich bisher verstanden habe, spricht da nichts gegen.
Rolf
Hallo Rolf,
die entsprechende $idlist vorab selektiert. Oder wie siehst Du das?
Nein, andersrum. Das ist eine dritte Query und Du hast Aufwand, die $idlist zu erzeugen. Das ist aus meiner Sicht nur nötig, wenn die eingebauten LIMIT Optimierungen von MYSQL nicht reichen.
Ich denke aber, dass DISTINCT, GROUP BY und SQL_CALC_FOUND_ROWS genau diese Optimierungen aushebeln und die Query langsam machen. Erster Versuch sollte deshalb sein, den GROUP BY und das SQL_CALC_FOUND_ROWS wegzubekommen. Soweit ich Dich bisher verstanden habe, spricht da nichts gegen.
Habe aber gerade aus Spaß an der Freud mal "DISTINCT, GROUP BY und SQL_CALC_FOUND_ROWS" unabhängig vom Ergebnis weggelassen und die Query war eher lahm. Ich hoffe, mir hat vorhin nicht der Cache einen Streich gespielt. Ich hatte deshalb eigens die ID-List-Reihen variiert.
Na ok. Wie schaffen wir, den Group By wegzulassen mithilfe der neuen Information zur "bezahlt-Spalte", das ist es, worauf wir gerade abzielen, nicht wahr?
Jörg
Hallo Rolf,
tut mir leid, heute kommen meine Antworten stückweise - sozusagen immer dann, wenn ich wieder eine habe 😉
Du schreibst, es könnte mehrere Zahlungseingänge zu einer Rechnung geben. Was hat es denn dann mit der Spalte ze.bezahlt auf sich? Hier kommt wieder der GROUP BY Konflikt ins Spiel. Wenn es 3 Zahlungseingänge gibt und nicht alle den gleichen Wert für "bezahlt" haben - welcher dieser Werte gehört dann ins Ergebnis? Was sagt "bezahlt" bei den Zahlungseingängen überhaupt aus?
Im Grunde ist die Spalte "bezahlt" in der Zahlungseinganstabelle nicht korrekt. Die gehört ansich in die Rechnungentabelle. Nun steht sie aber in der Zahlungseingangstabelle. Sie bedeutet einfach nur, ob mit dem Zahlungseingang die RG restlos bezahlt ist. Ist das der Fall, steht eine 1 drin, ist das nicht der Fall, steht eine 0 drin.
Bei der Datev kann man es mit einem Subselect lösen. Schreibe statt
da.ListenIDeinfach dies in die Spaltenliste des SELECT - ähnlich wie bei den Bruttozahlungen:(SELECT ListenID FROM daten_belege WHERE belegID=r.rechnungenID LIMIT 1) AS ListenID,
Ok, habe ich gemacht.
Wenn Du nur noch Einzelsätze hinzujoinst, sollte sich der GROUP BY erledigt haben. Dafür muss allerdings zuerst geklärt werden, wie mit der Spalte ze.bezahlt bei mehreren Zahlungseingängen umzugehen ist.
Naja, eigentlich benötige ich nur die Info, ob wenigstens 1 x eine 1 in der Spalte steht. Normalerweise sollte auch die Eingabe neuer Zahlungen gesperrt sein, sobald in dieser Spalte eine 1 steht. Insofern könnte man also auch sagen, dass nur der Wert der höchsten ID, zugehörig zur jeweiligen RechnunhgsID für die Spalte "bezahlt" relevant ist. Denn steht dort eine 0, ist die RG noch unbezahlt, steht dort eine 1, ist sie bezahlt.
Die Eindeutigkeit kannst Du dann im phpMyAdmin validieren, indem Du zwischen GROUP BY Klausel und ORDER BY Klausel ein
HAVING COUNT(*) > 1einfügst. Natürlich nicht in der PHP Anwendung. Die HAVING-Klausel ist sozusagen ein zusätzliches WHERE, das nach dem GROUP BY ausgeführt wird. Der Gezeigte HAVING liefert Dir alle Rechnungsnummern, für die es vor dem GROUP BY mehr als einen Satz gab.
Ja, verstehe.
Jörg
Hallo Jörg,
(ze.bezahlt)
Wenn Du keine Chance hast, die DB umzustrukturieren, dann... tja. Verbuche es unter "Data modeling - lessons learned". Es lohnt sich immer, über jedes Attribut in einer DB nachzudenken, ob es in der richtigen Relation ist.
Naja, eigentlich benötige ich nur die Info, ob wenigstens 1 x eine 1 in der Spalte steht. Normalerweise sollte auch die Eingabe neuer Zahlungen gesperrt sein, sobald in dieser Spalte eine 1 steht.
Dann könnte man ja einen SELECT MAX(bezahlt) machen.
Aber wenn Du es im Programm so löst, dass in dem Moment, wo genug Zahlungen eingegangen sind um den Rechnungsbetrag zu erfüllen, in allen Zahlungseingängen zur Rechnung die bezahtl-Spalte auf 1 gesetzt wird, kannst Du auch meinen LIMIT 1 Vorschlag nehmen. Wenn in Raten gezahlt wurde, ist der schneller. Mit MAX(bezahlt) müssen auf jeden Fall alle Sätze gelesen werden.
Habe aber gerade aus Spaß an der Freud mal "DISTINCT, GROUP BY und SQL_CALC_FOUND_ROWS" unabhängig vom Ergebnis weggelassen und die Query war eher lahm.
Um Cache-Effekte zu beseitigen, muss man die Query mehrfach ausführen. Dann ist der Cache auf jeden Fall gefüllt.
Um den Cache sicher zu leeren, muss man den Datenbankdienst einmal durchstarten. Das setzt natürlich voraus, dass man eine Testdatenbank hat, deren Serverdienst man kontrollieren kann. Bei einem Hoster geht's eher nicht. Aber Du kannst probieren, ob Du "FLUSH TABLES" ausführen darfst.
Bei einem Hoster sind Laufzeitmessungen auch nicht unbedingt repräsentativ. Wenn auf einem MYSQL Dienst einhundertunddrölf Datenbanken laufen, können die Konkurrenten mal aktiv sein und mal ein Päuschen machen. MÖGLICHERWEISE ist beim DB Hoster auch eine Leistungsstrafe eingebaut (obwohl ich nicht weiß, ob MYSQL sowas anbietet), mit der jemand, der in letzter Zeit viel DB-Leistung abgerufen hat, erstmal runterpriorisiert wird. Echte Laufzeitvergleiche musst Du auf einer Test-DB machen, auf der Du allein unterwegs bist.
Aber grundsätzlich ist jede Query, die länger als 1s läuft, für ein Onlinesystem viel zu langsam. Meine ich.
Rolf
Hallo Rolf,
Wenn Du keine Chance hast, die DB umzustrukturieren, dann... tja. Verbuche es unter "Data modeling - lessons learned". Es lohnt sich immer, über jedes Attribut in einer DB nachzudenken, ob es in der richtigen Relation ist.
Sehe ich genauso. Was mich ein bisschen ärgert, ist, dass diese DB-Struktur erst wenige jahre alt ist, d.h. ich hätte das zu diesem Zeitpunkt schon besser wissen sollen. Ich kann nur vermuten, dass ich mir dabei etwas gedacht habe. Aber ich habe es nicht dokumentiert.
Naja, eigentlich benötige ich nur die Info, ob wenigstens 1 x eine 1 in der Spalte steht. Normalerweise sollte auch die Eingabe neuer Zahlungen gesperrt sein, sobald in dieser Spalte eine 1 steht.
Dann könnte man ja einen SELECT MAX(bezahlt) machen.
Aber wenn Du es im Programm so löst, dass in dem Moment, wo genug Zahlungen eingegangen sind um den Rechnungsbetrag zu erfüllen, in allen Zahlungseingängen zur Rechnung die bezahtl-Spalte auf 1 gesetzt wird, kannst Du auch meinen LIMIT 1 Vorschlag nehmen. Wenn in Raten gezahlt wurde, ist der schneller. Mit MAX(bezahlt) müssen auf jeden Fall alle Sätze gelesen werden.
Das halte ich für eine gute Idee. Muss zwar mal darüber nachdenken, ob ich eine Historie benötige, ab wann die RG vollständig bezahlt war, aber vermutlich ist die entbehrlich. Und dass das nicht automatisch, sondern per Usereingabe auf bezahlt umgestellt werden soll, tut ja auchnnichts zur Sache bzgl. der Idee selber.
Aber grundsätzlich ist jede Query, die länger als 1s läuft, für ein Onlinesystem viel zu langsam. Meine ich.
Habe aber mal neue messungen gemacht und die Query liegt jetzt bei ca. 1 Sekunde. Heißt, es ist schon viel erreicht.
Leider dauert die Seite selber immer noch bis zu 10 Sekunden, was natürlich ein Unding ist. Es werden 50 RGs per Seite angezeigt und jeder Durchlauf der while-Schleife aus der Ergebnismange der Query braucht 0.15 bis 0.20 Sekunden. Ich frage mich allen Ernstes, wie ich da auf Werte unter 0.1 kommen soll. Ich mache halt mit jedem Datensatz noch ein paar Klimmzüge vor der Ausgabe. Ich fürchte, ich muss hier die Dynamik herausnehmen und einige Dinge statisch ablegen, damit sich diese Durchlaufzeiten nicht so horrend summieren.
Oder hast Du hierfür eine andere gute Idee?
Jörg
Hallo Jörg,
die Query liegt jetzt bei ca. 1 Sekunde.
Du hast gesagt, mit einer separaten ID Ermittlung kämest Du auf "ratzfatz". Es wäre dann vielleicht doch eine Maßnahme, das mal auszuprobieren. Aber das lohnt nicht, wenn...
jeder Durchlauf der while-Schleife aus der Ergebnismange der Query braucht 0.15 bis 0.20 Sekunden.
Was ist das? Reines PHP? Um aus dem Query Ergebnis das HTML für eine Rechnung zu erzeugen? Oder passiert da noch mehr?
Wenn Du einen Code-Review möchtest, den Code aber nicht öffentlich in ein Forum posten darfst/willst/kannst, dann registriere Dich hier als User, stelle den Code irgendwo versteckt online (Dropbox, Google Drive oder ähnlich) und schick mir als Privatnachricht im Forum einen Link darauf. Oder ich sag Dir dann meine private Mailadresse und du schickst ihn mir per Mail.
Rolf
Hallo Rolf,
die Query liegt jetzt bei ca. 1 Sekunde.
Du hast gesagt, mit einer separaten ID Ermittlung kämest Du auf "ratzfatz". Es wäre dann vielleicht doch eine Maßnahme, das mal auszuprobieren. Aber das lohnt nicht, wenn...
Ja, das war auch so. Die normale Query lag bei 6-8 Sekunden, die mit seperater ID-Ermittlung bei 0,0Irgendwas. Dann habe ich die mal testhalber in ein Produktivscript eingesetzt und stellte erschrocken fest, dass das Gesamtscript trotz seperater ID-Ermittlung wieder bei 8 Sekunden lag. 😟 Also muss dann doch in der Gesamt-While-Schleife der Ergebnismenge noch soviel Ballast stecken, dass ich mal nachgesehen habe. Deshalb kam ich dann mit dem Datenbestand dieser DB auf ca. 0,15 Sek / Datensatz. Ich verarbeite je Seite 50 Datensätze.
Was ist das? Reines PHP? Um aus dem Query Ergebnis das HTML für eine Rechnung zu erzeugen? Oder passiert da noch mehr?
Sowohl php als auch weitere Queries.
Wenn Du einen Code-Review möchtest, den Code aber nicht öffentlich in ein Forum posten darfst/willst/kannst, dann registriere Dich hier als User, stelle den Code irgendwo versteckt online (Dropbox, Google Drive oder ähnlich) und schick mir als Privatnachricht im Forum einen Link darauf. Oder ich sag Dir dann meine private Mailadresse und du schickst ihn mir per Mail.
Ich habe gerade heute nachmittag einen Useraccount angelegt, ich schicke Dir mal eine PN.
Jörg
 Rolf B
Rolf B