


Anzahl Max-Fibers bei vorgegebener Hardware
 Simone
Simone
- mysqli
- php
nicht angemeldetHallo,
hat jemand Erfahrung ab welcher Anzahl PHP-Fibers der Server aussteigt, oder ob es überhaupt eine Obergrenze gibt, die man austesten muss?
Ich verarbeite mit PHP per Konsole über 1 Million Jsons-Files und bereite diese für Mysql auf.
Hierbei versuche ich per Script möglichst das Maximum aus Serverhardware und Entwicklungsumgebung herauszuholen, finde jedoch keine Informationen, wie hoch der Aufrufstapel (Call-Stack) sein darf.
Vielen Dank ;o)

Hallo Simone,
ich habe mich mit Fibers noch nicht viel beschäftigt, aber aus der PHP Doku und aus dem "Simpel-Scheduler" Beispiel von Ali Madadi (hier) geht für mich hervor, dass es sich hierbei um eine Möglichkeit handelt, kooperatives Multitasking zu implementieren.
Also: Fibers sind keine Threads!
PHP ist single-threaded. Und Multitasking ist etwas anderes als Multithreading!
Multitasking: Der Computer hat mehrere Tasks zu erledigen und verteilt seine Leistung mehr oder weniger gerecht darauf. Entweder dadurch, dass die Tasks explizit die Kontrolle abgeben (kooperativ) oder dadurch, dass die Hardware den Task unterbricht und das Betriebssystem auf einen anderen umschaltet (präemptiv). Das gelingt auch mit nur einem CPU Kern und ist dann deutlich einfacher zu bändigen, wenn mehrere Tasks an einer gemeinsamen Aufgabe werkeln.
Multithreading: Multitasking mit mehr als einer CPU. Zwei Tasks können echt parallel ausgeführt werden. Die Herausforderungen und Fehlermöglichkeiten sind deutlich komplexer. Race-Conditions und das Fehlschlagen scheinbar einfacher Operationen wie $i = $i+1 können vorkommen.
Madadi spricht zwar von Multithreading, aber das ist falsch. PHP führt zu jedem Zeitpunkt genau eine Codestelle aus. Entweder das Hauptprogramm, oder einen der Fibers.
Ein Fiber kann sich unterbrechen, dann kehrt die Ausführung zum Hauptthread zurück. Und nur der Hauptthread kann eine Fiber mit resume weiterlaufen lassen. Aber dann bleibt der Hauptthread genau dort stehen und erst dann, wenn der Fiber suspend aufruft oder endet, kommt der resume-Aufruf im Haupthhread wieder zurück.
D.h. mit Fibers kann man kooperatives Multitasking mit Datenaustausch implementieren. Oder, wie Madadi, ein präemptives Multitasking, wenn man die Task-Fibers über die den tick-Handler brutal unterbricht. Aber zu einem Zeitpunkt läuft immer nur ein Task, und das Hauptprogramm ist in der Pflicht, alle Fibers zu orchestrieren und dafür zu sorgen, dass alle aktiven Fibers irgendwann einen resume bekommen.
Du schreibst, dass Du JSON-Files für MYSQL aufbereitest. D.h. du liest eine JSON-Datei, machst was damit und schreibst das Ergebnis in die Datenbank?
Mal angenommen, dass MYSQLI_ASYNC bei Updates überhaupt greift, dann kannst Du natürlich N Fibers erstellen, die eine JSON-Datei lesen und asynchron ein Update anstoßen. Dass der Update asynchron ist, ist dabei entscheidend, denn andernfalls gewinnst Du gar nichts durch die Fibers. Denn das Einlesen und Verarbeiten der JSONs läuft synchron. Nach dem mysqli_query kann der Fiber sich mit Fiber::suspend() schlafen legen. Der Hauptthread muss dann, nachdem er N Fibers gestartet hat, alle Fibers im Kreis resumen. Diese pollen, ob eine Antwort da ist. Wenn ja wird sie verarbeitet, wenn nicht, muss weiter gewartet werden. Über ihren Rückgabewert kann die Fiber mitteilen, ob sie weiter warten muss oder nicht. Ist eine Fiber fertig, kann für diese Connection eine neue Fiber mit der nächsten Datei gestartet werden.
Alles sehr komplex, aufwändig zu entwickeln und schwierig zu testen. Aber immerhin kann MYSQL dann im Hintergrund arbeiten und die Daten wegschreiben.
Allzuviele Fibers solltest Du aber nicht starten. Denn zum einen bleibt die JSON-Verarbeitung synchron, und zum anderen ist es nicht gesund für die Performance einer DB, wenn sie von zu vielen Verbindungen INSERTs oder UPDATEs auf die gleiche Ressource bekommt. Die Frage nach der maximalen Fiber-Zahl ist deshalb eigentlich nicht relevant. Der SQL Server ist viel schneller am Ende als PHP.
Aus meiner Sicht ist die etwas bessere und unkompliziertere Idee auch eigentlich, einfach mehrere Kommandozeilen aufzumachen und in jeder eine Instanz des Importprogramms zu starten. Es muss irgendwie mitbekommen, welchen Bereich der JSONs es verarbeiten soll, und verarbeitet die dann schön und unkompliziert und synchron nacheinander. Vorteil 1: echtes Multithreading, auch für die JSON-Verarbeitung. Vorteil 2: Du musst keinen Fiber-Scheduler handschnitzen. Wieviele Kommandozeilen? Im Zweifelsfalle probieren, wo das Maximum ist. Du hast eine CPU mit 4 Cores und Hyperthreading. D.h. maximal 8 aktive Threads, wobei Hyperthreading schnell in die Knie geht, wenn man alle Threads nutzen will. Aber solange ein PHP auf die DB wartet, ist Zeit für andere PHP Threads, also könntest Du mit 5 oder sogar 6 PHPs davonkommen. Aber 6 könnte schon kontraproduktiv sein. Oder läuft die DB auf einem anderen Computer?
Die beste Idee ist aber vielleicht eine ganz andere: Einzelne INSERTs oder UPDATEs sind auch eigentlich nicht das Mittel der Wahl für einen Massen-Import. Dafür verwendet man LOAD DATA INFILE. Dein PHP sollte hergehen und die JSON-Files in eine Eingabedatei für LOAD übersetzen (oder mehrere, wenn es mehr als eine Table ist) und danach haust Du die Daten in einem Rutsch in die DB. Das geht natürlich nur, wenn Du eine LOAD-Berechtigung hast und wenn Du diese Dateien konfliktfrei vorbereiten kannst. Wenn jede JSON-Datei zu komplizierten Updates in der DB führt, dann geht das nicht. Alternativ zum LOAD Statement gibt's auch das Kommandozeilentool mysqlimport (mariadb-import) für Massenimports. Wenn Du sowas öfter machst und entsprechende Rechte hast, solltest Du Dich definitiv damit beschäftigen.
Ich selbst habe das auf MYSQL noch nicht gemacht, meine Massendatenzeiten waren auf IBM Mainframes mit DB2, aber wenn ich da regelmäßig in einem Batchjob eine Million Datensätze hätte INSERTen wollen, dann wären mir die DB-Admins sehr schnell und sehr lautstark auf's Dach gestiegen. Sowas bremst die Kiste nämlich gewaltig aus.
Rolf
Hallo Rolf,
vielen Dank für Deinen Input ;o) es ist schön, dass es das Forum gibt!
MYSQLI_ASYNC werde ich testen bzw. kannte ich noch nicht.
Alles sehr komplex, aufwändig zu entwickeln und schwierig zu testen. Aber immerhin kann MYSQL dann im Hintergrund arbeiten und die Daten wegschreiben.
Nein, Fibers sind einfach zu implementieren und "PHP-Hauseigen" das ist sehr cool... finde ich
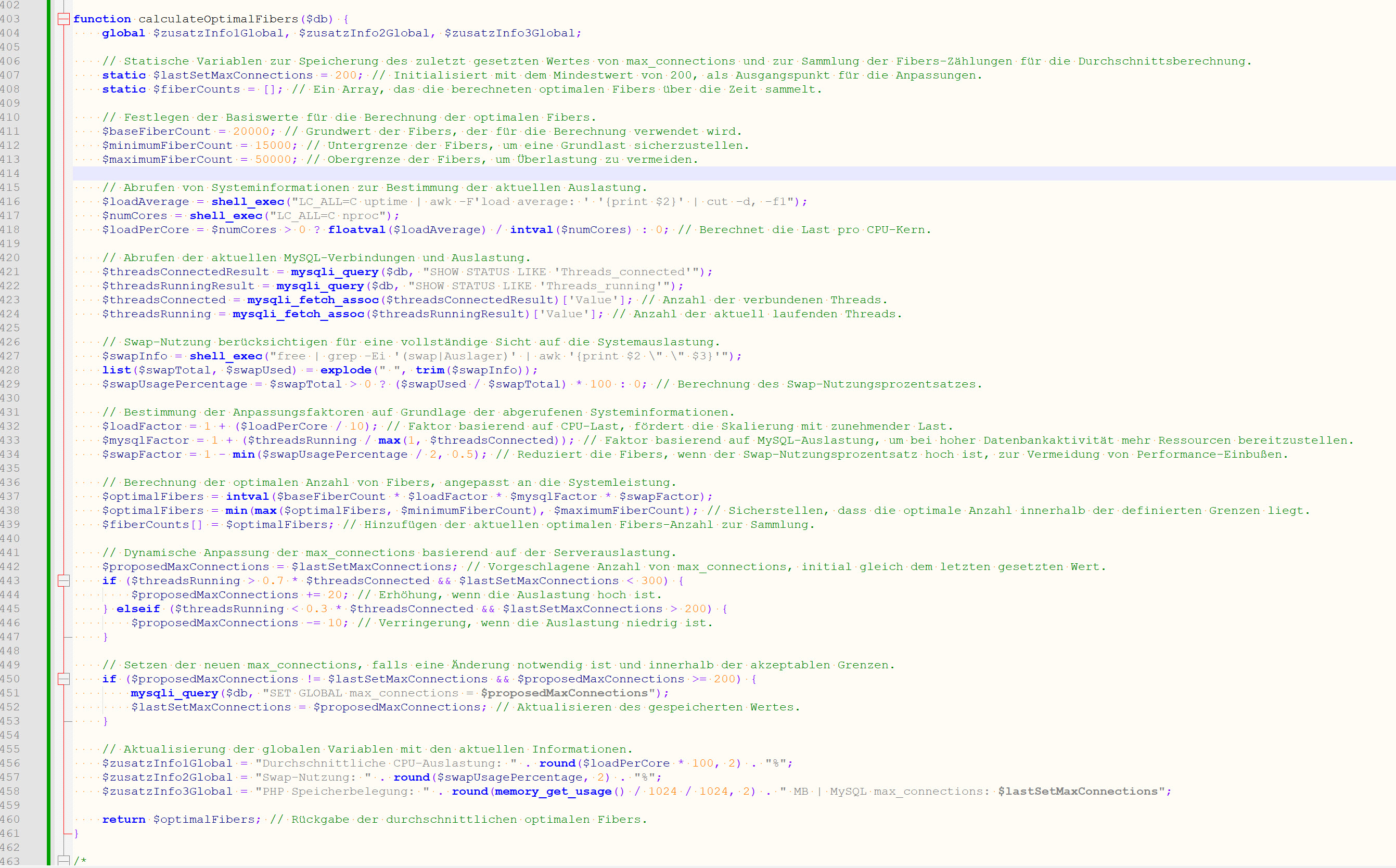
/**
* Verwaltet die Ausführung von Fibers für asynchrone Verarbeitung.
*
* @param array &$activeFibers Referenz auf das Array aktiver Fibers.
* @param mysqli $conn_ln Datenbankverbindung.
* @param array &$idsToProcess Referenz auf das Array der zu verarbeitenden Dateipfade.
* @param int &$nichtGefundenCount Zähler für nicht gefundene Json-Arrays und defekte JsonContent.
* @param bool $waitForAll Gibt an, ob auf die Beendigung aller Fibers gewartet werden soll.
*/
function manageFibersMysql(&$activeFibers, $conn_ln, $totalFiles, $startTime, $maxFibers, &$idsToProcess, &$nichtGefundenCount, $waitForAll = false) {
foreach ($idsToProcess as $filePath) {
$fiber = new Fiber(function () use ($filePath, $conn_ln,$totalFiles, $startTime, $maxFibers, &$nichtGefundenCount) {
$content = readAndParseJsonMysql($filePath);
if ($content) {
$result = processStelleJsonContent($content, $conn_ln, $totalFiles, $startTime, $maxFibers);
if ($result['nichtGefunden']) {
$nichtGefundenCount++;
}
}
});
$fiber->start();
$activeFibers[] = $fiber;
}
if (!$waitForAll) {
// Bereinige das Array für den nächsten Batch
$idsToProcess = [];
}
// Wenn waitForAll aktiv ist, warte bis alle Fibers ihre Arbeit beendet haben
if ($waitForAll) {
foreach ($activeFibers as $index => $fiber) {
if (!$fiber->isTerminated()) {
$fiber->resume();
} else {
unset($activeFibers[$index]);
}
}
// Nach dem Warten, bereinige auch hier das Array für den nächsten Batch
$activeFibers = [];
}
}
Aus meiner Sicht ist die etwas bessere und unkompliziertere Idee auch eigentlich, einfach mehrere Kommandozeilen aufzumachen
Ja! Diesen Ansatz hatte ich bei der Programmentwicklung auch, jedoch läuft die Geschichte im Hintergrund lokal per Cronjob... bis es komplett fertig durchgelaufen ist greift:
$lockFile = fopen(__LOCK_FILE__, 'c+');
if (!$lockFile) {
error_log("Fehler: Konnte Lock-Datei nicht öffnen.\n", 3, __DIR__ . '/errorlogphp/errorlogphp.log');
exit("Fehler: Konnte Lock-Datei nicht öffnen.\n");
}
if (!flock($lockFile, LOCK_EX | LOCK_NB)) {
fclose($lockFile);
exit();
}
es muss nur eine angemessene Verarbeitungszeit herauskommen! es läuft nichts anderes auf dem NUC-Rechner. Datengewinnen und aufbereiten.
Ich gehe von Datenmengen nach ca. einen Jahr von ca. 23 Millionen Datensätzen aus. Das schafft ein Mini-PC und Mysql nicht mehr zu verarbeiten / denke ich... es seiden es wird rudimentär auf Verzeichnisebene gearbeitet, als bekommt jede *.jsons ein eigenes Verzeichnis wo ich per touch das Modifi-Datum vom Verzeichnis änder sollte ein Update notwendig sein wird das modif-Datum genutzt. Na mal sehen wie robust das wirklich ist nach einem Jahr.
Ich werde Deinen Beitrag meiner Programm-Dokumentation hinzufügen.
Beste Grüße und nochmal Danke Rolf!
Für die Nachwelt hier habe ich Fibers mit unterschiedlichen Anfangswerten getestet. Hier stellte sich heraus das die ursprüngliche / intuitive Config am besten geeignet ist.
Hallo Simone,
dein Codebeispiel zeigt einen Fiber-Scheduler, ähnlich dem, wie er auch im PHP Handbuch gezeigt wird. Aber er ist buggy - falls deine Fibers mehr als einen suspend-Aufruf erhalten, wird er nach dem zweiten Suspend nicht mehr zurückkommen.
Nochmal: Fibers sind keine Threads. Solange im Fiber-Code kein Fiber::suspend() steht, läuft der Fiber komplett im start() Aufruf durch, womit die Fibers vergebliche Mühe sind. Dein Code wird dann niemals an die Stelle kommen, wo resume aufgerufen wird.
Wenn Du die SQL-Statements nicht asynchron absetzt, hast Du auch keinen Ort im Code, wo Dir ein suspend etwas nützen könnte. Du kannst zwar nach einem nicht-asynchronen SQL Statement Fiber::suspend() aufrufen, aber du gewinnst damit nichts.
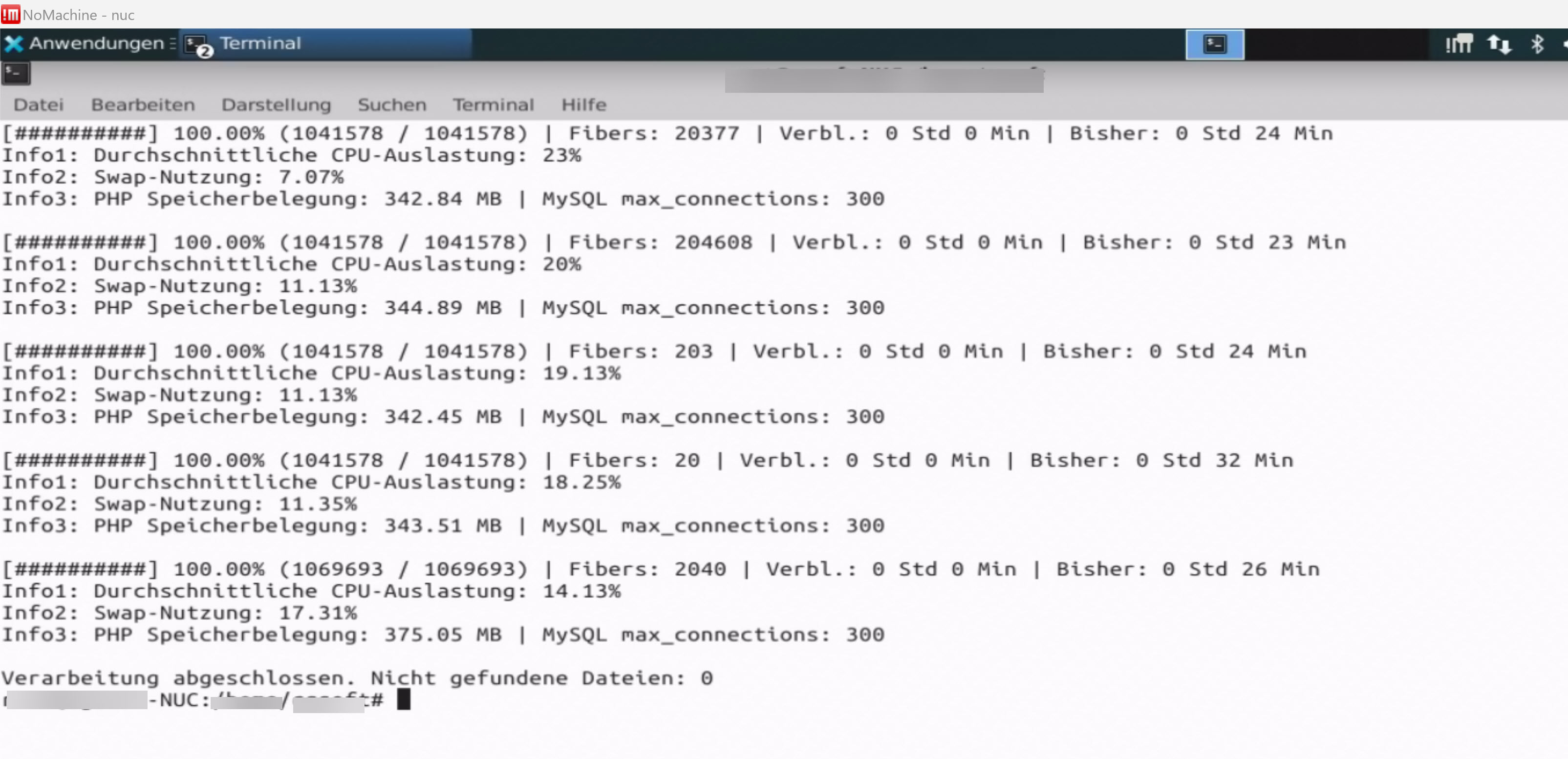
Dein Log zeigt ja auch, dass die Fibers die Laufzeit nicht wesentlich beeinflussen. Bei einer Million Logfiles sind Schwankungen von 3 Minuten nicht ungewöhnlich. Den Ausreißer bei 20 Fibers kann ich aber nicht erklären.
Dass bei 20000 Fibers und 200000 Fibers der Speicherbedarf fast gleich ist, ist ebenfalls ein Hinweis. Ohne suspend läuft jeder Fiber komplett durch und es wird kein Speicher gebraucht, um seinen Kontext zu speichern. Mit asynchronem SQL und vorhandenem suspend würde dein Programm auch abstürzen, denn es scheint, als hättest Du nur eine einzige SQL Connection offen ($conn_ln).
Natürlich mag ich mich irren, weil ich nicht den ganzen Code sehe. Aber bisher habe ich den Eindruck, dass Du eine wunderschön geformte und mit einem prächtigen Etikett versehene Flasche voller – Schlangenöl zubereitet hast.
Rolf
Ja, klasse Antwort
ich habe das nochmal gecheckt, das funktioniert so nicht ohne einen Scheduler der die Fibers verwaltet. Hm, ich schaue mal, wo der Weg hinführt.
Fiber-Code kein Fiber::suspend()
na dann wirds eben synchron innerhalb des Fibers ausgeführt ;O) und der Array mit den *.jsons ggf. aufgesplittet
Jeder Fiber wird sofort gestartet ($fiber->start();) und führt seine Aufgabe komplett durch. Da wir Fiber::suspend() nicht verwenden, gibt es keine Notwendigkeit, Fiber::resume() aufzurufen, außer in einem Wiederholungszyklus, falls ein Fiber noch läuft.
Die Funktion überprüft die Anzahl der aktiven Fibers gegen eine maximale Grenze ($maxFibers), um die Systemressourcen zu schonen. Wenn waitForAll true ist, wartet die Funktion in einer Schleife, bis alle Fibers ihre Arbeit abgeschlossen haben. Dies wird durch Überprüfen des Status jedes Fibers erreicht.
Fibers, die ihre Arbeit abgeschlossen haben, werden aus dem Array der aktiven Fibers entfernt, wodurch verhindert wird, dass beendete Fibers unnötig weiterverarbeitet werden.
function manageFibersMysql(&$activeFibers, $conn_ln, $totalFiles, $startTime, $maxFibers, &$idsToProcess, &$nichtGefundenCount, $waitForAll = false) {
foreach ($idsToProcess as $index => $filePath) {
// Starte einen neuen Fiber nur, wenn die maximale Anzahl von Fibers nicht überschritten ist
if (count($activeFibers) < $maxFibers) {
$fiber = new Fiber(function () use ($filePath, $conn_ln, $totalFiles, $startTime, $maxFibers, &$nichtGefundenCount) {
$content = readAndParseJsonMysql($filePath);
if ($content) {
$result = processStelleJsonContent($content, $conn_ln, $totalFiles, $startTime, $maxFibers);
if ($result['nichtGefunden']) {
$nichtGefundenCount++;
}
}
});
$fiber->start();
$activeFibers[] = $fiber;
unset($idsToProcess[$index]); // Entferne die verarbeitete ID aus der Liste
}
}
if ($waitForAll) {
// Warte, bis alle Fibers ihre Arbeit beendet haben
while (!empty($activeFibers)) {
foreach ($activeFibers as $index => $fiber) {
if ($fiber->isRunning()) {
// Wenn Fiber noch läuft, lass ihn weiterlaufen
continue;
} elseif ($fiber->isTerminated()) {
// Wenn Fiber beendet ist, entferne ihn aus der Liste
unset($activeFibers[$index]);
}
}
}
}
// Wenn nicht auf alle gewartet werden soll, wird der Zustand der Fibers nicht geprüft
// und die Steuerung kehrt sofort zurück.
}
Ich laufe die Funktion jetzt mal damit durch
$globalAsyncQueries = [];
$queryCounter = 0;
function addAsyncQuery($db, $sql) {
global $globalAsyncQueries, $queryCounter;
$queryID = 'query_' . ++$queryCounter . '_' . microtime(true);
$globalAsyncQueries[$queryID] = ['db' => $db, 'sql' => $sql, 'id' => $queryID];
}
function executeAllAsyncQueries($ende) {
global $globalAsyncQueries;
if (empty($globalAsyncQueries)) {
//echo "Keine Anfragen vorhanden in globalAsyncQueries.\n";
return false;
}
if (count($globalAsyncQueries) < 100 && !$ende) {
//echo "Es müssen mindestens 100 Anfragen vorhanden sein, oder 'ende' muss true sein. Aktuelle Anzahl: " . count($globalAsyncQueries) . "\n";
return false;
}
// Neue Logik: Entferne die Notwendigkeit einer separaten DB-Instanz pro Anfrage.
// Stattdessen wird $db innerhalb der Schleife aus dem globalen Array bezogen.
foreach ($globalAsyncQueries as $queryID => $query) {
$sql = $query['sql'];
// Erstelle hier eine neue Datenbankverbindung, falls erforderlich
$localDb = $query['db']; // Angenommen, dies ist bereits eine gültige Verbindung
if (empty($sql)) {
echo "SQL-Anfrage ist leer (ID: $queryID).\n";
continue;
}
if (!$localDb->query($sql, MYSQLI_ASYNC)) {
echo "Fehler beim Senden der asynchronen Anfrage (ID: $queryID): " . mysqli_error($localDb) . "\n";
continue;
}
// Warte, bis die Anfrage fertig ist, und verarbeite das Ergebnis.
// Dies ist eine vereinfachte Darstellung, die angepasst werden muss.
do {
$links = $errors = $reject = [$localDb];
mysqli_poll($links, $errors, $reject, 0, 50000);
} while (empty($links));
foreach ($links as $link) {
if ($result = $link->reap_async_query()) {
if (is_object($result)) {
mysqli_free_result($result);
}
// Entferne die abgearbeitete Anfrage.
// Debug-Funktion aufrufen, um die Operation zu überprüfen
// debugDatabaseOperations($link, $queryID);
unset($globalAsyncQueries[$queryID]);
}
}
}
//echo "Alle Anfragen wurden erfolgreich abgeschlossen.\n";
return true;
}
function debugDatabaseOperations($localDb, $queryID) {
// Überprüfe die Anzahl der betroffenen Zeilen
$affectedRows = $localDb->affected_rows;
// Überprüfe auf Fehler
if ($localDb->errno) {
echo "Fehler bei der Ausführung der Anfrage (ID: $queryID): " . $localDb->error . "\n";
} elseif ($affectedRows === 0) {
echo "Keine Zeilen betroffen oder eingefügt für Anfrage (ID: $queryID). Überprüfe die Logik deiner Anfrage.\n";
} else {
echo "Anfrage (ID: $queryID) erfolgreich ausgeführt. Betroffene/eingefügte Zeilen: $affectedRows\n";
}
// Zusätzliche Informationen
if ($affectedRows > 0) {
// Hier könnten weitere Debug-Informationen eingefügt werden,
// wie z.B. die Ausgabe der tatsächlich eingefügten oder aktualisierten Daten.
}
}
Hallo Simone,
oha. Das sieht komplex aus 😉
na dann wirds eben synchron innerhalb des Fibers ausgeführt ;O) und der Array mit den *.jsons ggf. aufgesplittet
Jeder Fiber wird sofort gestartet ($fiber->start();) und führt seine Aufgabe komplett durch.
Und was ich Dir klarmachen will, ist, dass Du dann auf die Fibers komplett verzichten kannst. Weil sie Dir nur technischen Overhead bescheren.
Sehe ich das im neuen Code richtig, dass processStelleJsonContent mittels addAsyncQuery in $globalAsyncQueries eine Anzahl Queries hinterlegt und diese dann mit executeAllAsyncQueries() ausgeführt werden?
Und zwar mit MYSQLI_ASYNC, gefolgt von einer Warteschleife, die auf das Ende der asynchronen Query wartet?
Sehe ich das richtig, dass executeAllAsyncQueries() nicht in den Fibers läuft, sondern unabhängig davon?
Wenn das so ist, kannst Du auch auf die async Queries komplett verzichten. Du hast die Query zwar asynchron gestartet, wartest danach aber in einer Schleife auf's Ergebnis und machst sie damit wieder synchron.
D.h. du hast Dir eine Menge technischen Overhead geschaffen, und er bringt Dir keinerlei Performancevorteile.
Dein Design braucht einen Neuanfang, um die Fibers wirklich nutzen zu können.
Du kannst für jede Json-Datei eine Fiber erzeugen. Okay. Die Fiber-Funktion sollte
die JSON-Datei lesen
die gelesenen Daten für das DB-Update vorverarbeiten
eine DB Connection öffnen
für jedes erforderliche DB-Update
die DB Connection schließen
Mit Returncode FALSE zurückkehren
Im Fiber-Manager musst Du, nachdem alle Fibers gestartet sind, die Fiberliste solange immer wieder durchgehen und resume aufrufen, bis alle Fibers isTerminated gemeldet haben.
Auf diese Weile bekommst Du es hin, die Zeit, die die Queries auf dem DB Server verbringen, sinnvoll für andere Dinge zu nutzen. Aber wie gesagt: Nicht zu viele Fibers. Es ist schädlich, aus 100 SQL Connections heraus gleichzeitig Updates zu ballern. Eine Parallelisierung dieser Art setzt auch voraus, dass die Inserts oder Updates, die aus einer JSON-Datei entstehen, von denen aller anderen JSON-Dateien unabhängig sind. Wenn Du fachlich mehrere Abläufe parallel durchführst, ist diese Unabhängigkeit sehr wichtig, andernfalls erzeugst Du Datensalat.
Rolf
Hallo Rolf,
Dein Design braucht einen Neuanfang
Es war eine coole Idee
"back to the roots" ...
MYSQLI_ASYNC raus Transaktionen rein. Fiber raus.
To-do PHP-Ausführung mehrfach in den Hintergrund und die Bearbeitung aufgesplittet.
/**
* Startet einen Befehl im Hintergrund.
* @param string $exec Der auszuführende Befehl.
*/
function go_hintergrund($exec) {
$descriptorspec = [
0 => ["pipe", "r"],
1 => ["pipe", "w"],
2 => ["pipe", "w"]
];
$process_db = proc_open($exec, $descriptorspec, $pipes);
}
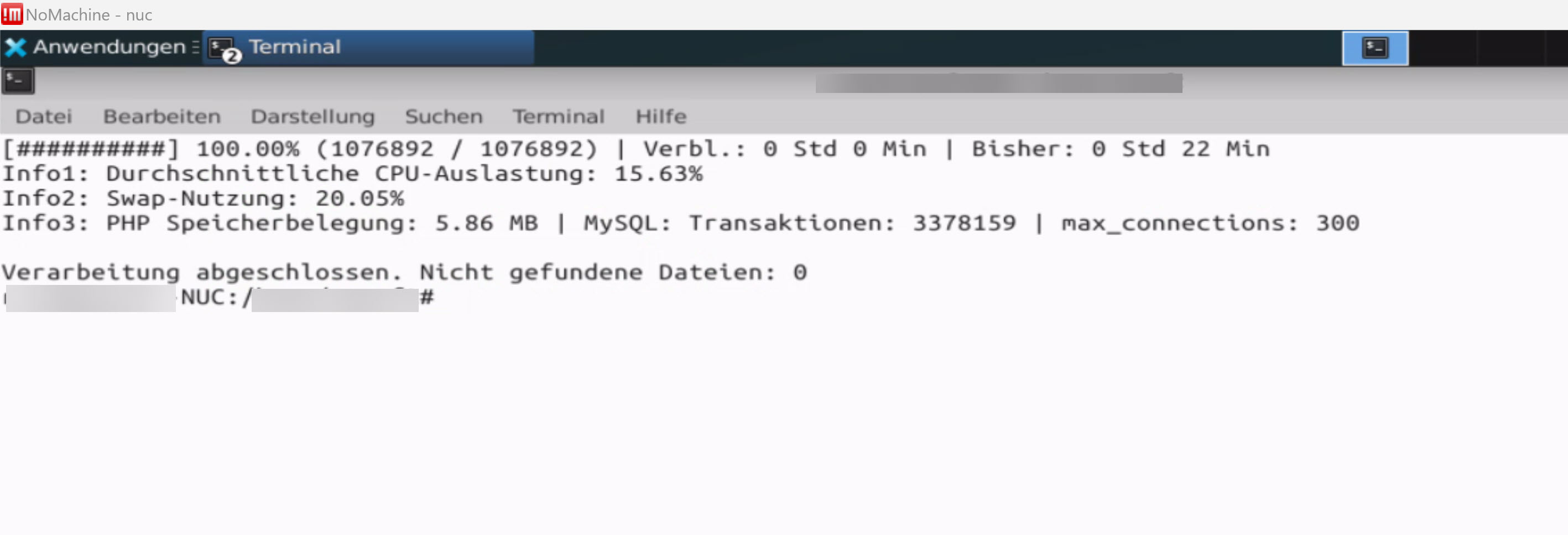
Ok, an der Ausführungszeit hat sich nicht viel geändert ;o) aber es sind ja auch 3.3 Millionen Transaktionen zu verarbeiten.
Danke Dir für Deine "Denk-Impulse" manchmal kommt man vom Weg ab
@@Simone
@Dein Design braucht einen Neuanfang
Das Zeichen zur Kenntlichmachung von zitierten Stellen aus dem Vorposting hier im Forum ist >, nicht @. Ich hab das in deinen Postings mal geändert.
Kwakoni Yiquan
 Rolf B
Rolf B Gunnar Bittersmann
Gunnar Bittersmann