Hallo T-Rex,
Hinzu kommt, dass ich schlafende Windows Kerne aufgeweckt habe: https://www.youtube.com/watch?v=e7msQDa5jVc
Ich bin zwar nicht der absolute Prozessorspezialist - aber ich würde das, was da im Video passiert, ins Märchenreich verweisen.
Wenn Du eine CPU mit Hyperthreading hast, dann kann der Prozessor konkurrierende Threads besser parallel ausführen, ja. Wenn Du 8 Threads hast, dann könnte es sein, dass ein Prozessor mit 4 Kernen und Hyperthreading diese in Summe schneller ausführt als ein Prozessor mit 4 Kernen OHNE Hyperthreading. Muss aber nicht sein.
Sowas muss man nicht "aufwecken". Und schon gar nicht über die Leistungsüberwachung, denn das ist genau das, was der Name sagt: eine Überwachung des Ist-Zustandes, weiter nichts. Sie ändert nichts an der CPU-Konfiguration. Es könnte sein, dass die aktive Leistungsüberwachung mit der Idle-Messung des Taskmanagers kollidiert und der Taskmanager deshalb andere Auslastungswerte anzeigt.
Dass ein normaler Desktopprozessor Kerne hat, die eigentlich nur bei Schäden einspringen und die man für den laufenden Betrieb hinzunehmen kann, halte ich für eine Erfindung. Es mag Serverprozessoren im High Availability Bereich geben, die sowas tun. Also die richtig teuren Xeons. Aber an diese Reservekerne kommst Du für den Normalbetrieb nicht heran. Weil sich Dein Prozessor sonst in einen Elefantenfuß verwandelt, bevor er durch's Motherboard tropft - Stichwort Thermal Design Power.
Ob dein Prozessor Hyperthreading besitzt, erfährst Du am zuverlässigsten über die Typenbezeichnung und beispielsweise diese Liste.
Er muss es aber nicht nur haben, es muss auch noch eingeschaltet sein. Die Wahrheit findest Du (Windows 10) im Taskmanager, "Leistung" Tab, Abteilung "CPU". Unter den Auslastungskurven siehst Du sowas:
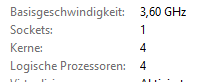
Mein Computer hat kein Hyperthreading, weil Kerne und logische Prozessoren gleich sind. Die meisten i5-er haben keins, die i7-er schon. Man kann es im BIOS ein- und ausschalten.
Warum? Weil es nicht immer sinnvoll ist. Je nach Workload kann Hyperthreading das Gerät auch bremsen. Das hat Gründe:
- mehr CPU Aktivität bedeutet mehr Wärme. Wenn deine Kühlung nicht ausreicht, taktet der Prozessor ggf. herunter, wenn Du ihn mit Hyperthreading quälst
- Hyperthreading bedeutet, dass ein Kern 2 Threads bearbeitet. Der Trick ist dabei, dass ein CPU Kern aus sehr vielen Baugruppen besteht, die nicht immer alle gleichzeitig arbeiten. Hyperthreading bedeutet, dass die "einfacheren" Teile des Kerns doppelt existieren und damit die komplexeren Teile des Kerns besser ausgelastet werden können. Vor vielen Jahren haben die Kollegen bei c't das mal gemessen. Die Leistungszuwachs lag längst nicht bei 200% - das wäre ja auch merkwürdig. Es sind eher 20% bis 30%.
- Wenn die Threads sehr speicherintensiv sind, überlastest Du mit zu vielen Threads ggf. den Prozessorcache, d.h. eine Verdopplung der Threads führt zu so vielen Cache Misses, dass Du unter dem Strich langsamer bist.
- je nach Betriebssystem kommt der Thread-Scheduler mit zu vielen Kernen nicht gut klar. Das war bei Windows vor Win7 der Fall, ist heute also irrelevant.
Gerade wenn viele PROZESSE parallel aktiv sind, bedeutet Hyperthreading richtig Stress für die Kiste. Denn jeder Prozess hat sein eigenes Speichermanagement (die Seitentabellen) und ein Kern, der zwei Prozesse hyperthreaden will, muss dafür ständig seine Speicherschaltkreise umschalten. Das ist teuer.
Und dass ein zu hohe Zahl an Threads generell kontraproduktiv ist, hast Du ja auch schon gemerkt. Der Prozessor beschäftigt sich dann mehr mit Kontextwechseln als eigentlicher Arbeit.
Rolf
--
sumpsi - posui - obstruxi



 T-Rex
T-Rex
 Rolf B
Rolf B
 TS
TS
 Der Martin
Der Martin

{kind=link}